
I. Ceph introduction
Ceph is a massively scalable, open source, distributed storage system. It is comprised of an object store, block store, and a POSIX-compliant distributed file system. The platform is capable of auto-scaling to the exabyte level and beyond, it runs on commodity hardware, it is self-healing and self-managing, and has no single point of failure. Ceph is in the Linux kernel and is integrated with the OpenStack™ cloud operating system. As a result of its open source nature, this portable storage platform may be installed and used in public or private clouds.
I.1. RADOS?
You can easily get confused by the denomination: Ceph? RADOS?
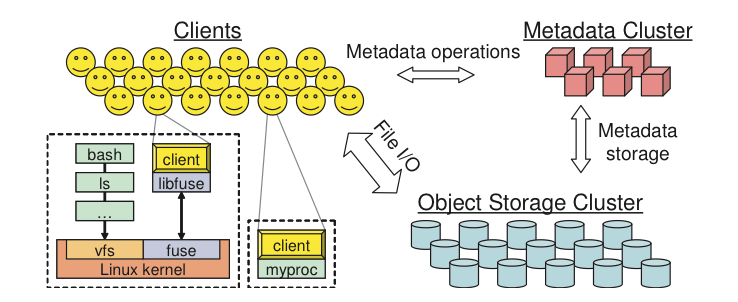
RADOS: Reliable Autonomic Distributed Object Store is an object storage. RADOS takes care of distributing the objects across the whole storage cluster and replicating them for fault tolerance. It is built with 3 major components:
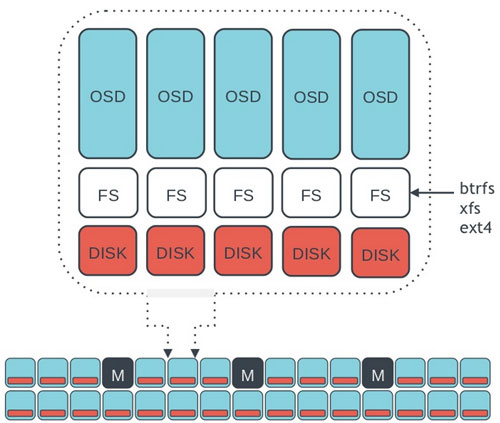
- Object Storage Daemon (OSD): the storage daemon - RADOS service, the location of your data. You must have this daemon running on each server of your cluster. For each OSD you can have an associated hard drive disks. For performance purpose it’s usually better to pool your hard drive disk with raid arrays, LVM or btrfs pooling. With that, for one server your will have one daemon running. By default, three pools are created: data, metadata and RBD.
- Meta-Data Server (MDS): this is where the metadata are stored. MDSs build POSIX file system on top of objects for Ceph clients. However if you are not using the Ceph File System, you do not need a meta data server.
- Monitor (MON): this lightweight daemon handles all the communications with the external applications and the clients. It also provides a consensus for distributed decision making in a Ceph/RADOS cluster. For instance when you mount a Ceph shared on a client you point to the address of a MON server. It checks the state and the consistency of the data. In an ideal setup you will at least run 3
ceph-mondaemons on separate servers. Quorum decisions and calculs are elected by a majority vote, we expressly need odd number.
Ceph devoloppers recommend to use btrfs as a filesystem for the storage. Using XFS is also possible and might be a better alternative for production environements. Neither Ceph nor Btrfs are ready for production. It could be really risky to put them together. This is why XFS is an excellent alternative to btrfs. The ext4 filesystem is also compatible but doesn’t take advantage of all the power of Ceph.
We recommend configuring Ceph to use the XFS file system in the near term, and btrfs in the long term once it is stable enough for production.
For more information about usable file system
I.2. Ways to store, use and expose data
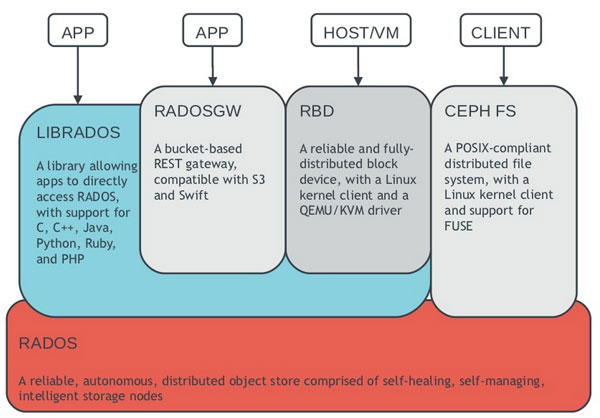
Several ways to store and access your data :)
- RADOS: as an object, default storage mecanism.
- RBD: as a block device. The linux kernel RBD (rados block device) driver allows striping a linux block device over multiple distributed object store data objects. It is compatible with the kvm RBD image.
- CephFS: as a file, POSIX-compliant filesystem.
Ceph exposes its distributed object store (RADOS) and it can be accessed via multiple interfaces:
- RADOS Gateway: Swift and Amazon-S3 compatible RESTful interface. For further information.
- librados and the related C/C++ bindings.
- rbd and QEMU-RBD: linux kernel and QEMU block devices that stripe data across multiple objects.
## I.3. IS CEPH PRODUCTION-QUALITY?
The definition of “production quality” varies depending on who you ask. Because it can mean a lot of different things depending on how you want to use Ceph, we prefer not to think of it as a binary term. At this point we support the RADOS object store, radosgw, and RBD because we think they are sufficiently stable that we can handle the support workload. There are several organizations running those parts of the system in production. Others wouldn’t dream of doing so at this stage. The CephFS POSIX-compliant filesystem is functionally-complete and has been evaluated by a large community of users, but has not yet been subjected to extensive, methodical testing.
II. Ceph installation
Relevant infrastructure schema:
Since there is no stable version, I decided to version with the upstream version of Ceph. Thus, I used the Ceph repository, I worked with the last version available so 0.47.2:
$ wget -q -O- https://raw.github.com/ceph/ceph/master/keys/release.asc | sudo apt-key add -
$ sudo echo "deb http://ceph.newdream.net/debian precise main" | sudo tee /etc/apt/sources.list.d/ceph.list
$ sudo apt-get update && sudo apt-get install ceph
Since I don’t have thousand nodes I decided to put every services on each node. Here my really basic Ceph configuration file:
; Ceph conf file!
; use semi-colon to put a comment!
[global]
auth supported = cephx
keyring = /etc/ceph/keyring.admin
[mds]
keyring = /etc/ceph/keyring.$name
[mds.0]
host = server-03
[mds.1]
host = server-04
[mds.2]
host = server-06
[osd]
osd data = /srv/ceph/osd$id
osd journal = /srv/ceph/osd$id/journal
osd journal size = 512
osd class dir = /usr/lib/rados-classes
keyring = /etc/ceph/keyring.$name
; working with ext4
filestore xattr use omap = true
; solve rbd data corruption
filestore fiemap = false
[osd.0]
host = server-03
devs = /dev/mapper/nova--volumes-lvol0
[osd.1]
host = server-04
devs = /dev/mapper/server-04-lvol0
[osd.2]
host = server-06
devs = /dev/sdb
[mon]
mon data = /srv/ceph/mon$id
[mon.0]
host = server-03
mon addr = 172.17.1.4:6789
[mon.1]
host = server-04
mon addr = 172.17.1.5:6789
[mon.2]
host = server-06
mon addr = 172.17.1.7:6789
Generate the keyring authentication, deploy the configuration and configure the nodes. I will highly recommand to previously setup a SSH key authentication based because mkcephfs will attempt to connect via SSH to each servers (hostnames) you provided in the ceph configuration file. It can be a pain in the arse to enter the ssh password for every command run by mkcephfs!
Directory creation is not managed by the script so you have to create them manually on each server:
server-03:~$ sudo mkdir -p /srv/ceph/{osd0,mon0}
server-04:~$ sudo mkdir -p /srv/ceph/{osd1,mon1}
server-06:~$ sudo mkdir -p /srv/ceph/{osd2,mon2}
Don’t forget to mount your OSD directory according to your disk map otherwise Ceph will by default use the root filesystem. It’s up to you to use ext4 or XFS. For those of you who want to setup an ext4 cluster I extremly recommend to use the following mount options for your hard drive disks:
user_xattr,rw,noexec,nodev,noatime,nodiratime,data=writeback,barrier=0
Now run the mkcephfs to deploy your cluster:
$ sudo mkcephfs -a -c /etc/ceph/ceph.conf -k /etc/ceph/keyring.admin
Ceph doesn’t need root permission to execute his command, it simply needs to access the keyring. Each Ceph command you execute on the command line assumes that you are the client.admin default user. The client.admin key has been generated during the mkcephfs process. The interesting thing to know about cephx is that it’s based on Kerberos ticket trust mecanism. If you want to go further with the cephx authentication check the ceph documentation about it. Just make sure that your keyring is readable by everyone:
$ sudo chmod +r /etc/ceph/keyring.admin
And launch all the daemons:
$ sudo service ceph start
This will run every Ceph daemons, namely OSD, MON and MDS (-a flag), but you can specify a particular daemon with an extra parameter as osd, mon or mds. Now check the status of your cluster by running the following command:
$ ceph -k /etc/ceph/keyring.admin -c /etc/ceph/ceph.conf health
HEALTH_OK
As you can see I’m using the -k option, indeed Ceph supports cephx secure authentication between the nodes within the cluster, each connection and communication are initiated with this authentication mecanism. It depends on your setup but it can be overkill to use this system…
All the daemons are running (extract from the server-04):
$ ps aux | grep ceph
root 22403 0.0 0.1 126204 7748 ? Ssl May23 0:35 /usr/bin/ceph-mon -i 1 --pid-file /var/run/ceph/mon.1.pid -c /etc/ceph/ceph.conf
root 22596 0.0 0.3 148680 13876 ? Ssl May23 0:08 /usr/bin/ceph-mds -i server-04 --pid-file /var/run/ceph/mds.server-04.pid -c /etc/ceph/ceph.conf
root 22861 0.0 59.8 2783680 2421900 ? Ssl May23 2:03 /usr/bin/ceph-osd -i 1 --pid-file /var/run/ceph/osd.1.pid -c /etc/ceph/ceph.conf
Summarize of your ceph cluster status:
$ ceph -s
pg v623: 576 pgs: 497 active+clean, 79 active+clean+replay; 11709 bytes data, 10984 MB used, 249 GB / 274 GB avail
mds e13: 1/1/1 up {0=server-06=up:active}, 4 up:standby
osd e15: 3 osds: 3 up, 3 in
log 2012-05-23 22:54:00.018319 mon.0 172.17.1.4:6789/0 10 : [INF] mds.0 172.17.1.7:6804/1187 up:active
mon e1: 3 mons at {0=172.17.1.7:6789/0,1=172.17.1.4:6789/0,2=172.17.1.5:6789/0}
You can also use the -w option to provide an endless and live output.
II.2. Make it grow!
It’s really easy to expand your Ceph cluster. Here I will add a logical volume.
$ ceph osd create
3
Copy this into your ceph.conf file:
[osd.3]
host = server-03
devs = /dev/mapper/nova--volumes-lvol0
Format, create the OSD directory, mount it:
$ sudo mkfs.ext4 /dev/mapper/nova--volumes-lvol0
$ sudo mkdir /srv/ceph/osd3
$ sudo mount /dev/mapper/nova--volumes-lvol0 /srv/ceph/osd3
Configure the authentifation, permission and grow the crunchmap:
$ ceph-osd -i 3 --mkfs --mkkey
$ ceph auth add osd.3 osd 'allow *' mon 'allow rwx' -i /etc/ceph/keyring.osd.3
$ sudo service ceph start osd.3
At the moment, the OSD is part of the cluster but doesn’t store any data, you need to add to the crush map:
$ ceph osd crush set 3 osd.3 1.0 pool=default host=server-03
The migration starts, wait a few seconds and verify the space available with the ceph -s command, you should notice that your cluster is growing.
You can also perform this check and see that your storage tree has grown as well:
$ ceph osd tree
dumped osdmap tree epoch 43
# id weight type name up/down reweight
-1 4 pool default
-3 4 rack unknownrack
-2 1 host server-03
0 1 osd.0 up 1
-4 2 host server-04
1 1 osd.1 up 1
3 1 osd.3 up 1
-5 1 host server-06
2 1 osd.2 up 1
I have 2 ‘resources’ on the server-04 because I added a logical volume.
II.3. Shrink your cluster
It’s remarkably simple to shrink your ceph cluster. First you need to stop your OSD daemon and wait until the OSD is marked as down.
$ ceph osd crush remove osd.1
removed item id 1 name 'osd.1' from crush map
$ ceph osd rm 1
marked dne osd.1
$ sudo rm -r /srv/ceph/osd1/
Remove this line from the ceph.conf file:
[osd.1]
host = server-03
When you work with OSD you will often see the crushmap term. But what is the crushmap?
CRUSH is a pseudo-random placement algorithm which tells where data (objects) should remain. The crush map contains these information.
II.4. Re build an OSD from scratch
Here I rebuilt the OSD number 1:
$ sudo service ceph stop osd
$ sudo umount /srv/ceph/osd1/
$ sudo mkfs.ext4 /dev/mapper/nova--volumes-lvol0
$ sudo tune2fs -o journal_data_writeback /dev/mapper/nova--volumes-lvol0
Copy this in your fstab:
/dev/mapper/nova--volumes-lvol0 /srv/ceph/osd1 ext4 rw,noexec,nodev,noatime,nodiratime,user_xattr,data=writeback,barrier=0 0 0
$ sudo mount -a
$ ceph mon getmap -o /tmp/monmap
$ ceph-osd -c /etc/ceph/ceph.conf --monmap /tmp/monmap -i 1 --mkfs
Finally run the OSD daemon:
$ sudo service ceph start osd
II.5. Resize an OSD
On an LVM based setup, stop the OSD server:
$ mount | grep osd
/dev/mapper/server4-lvol0 on /srv/ceph/osd1 type ext4 (rw,noexec,nodev,noatime,nodiratime,user_xattr,data=writeback,barrier=0)
$ sudo service ceph stop osd1
$ sudo umount /srv/ceph/osd1
Check your LVM status, here I resized my logical volume from 90G to 50G:
$ sudo lvs
LV VG Attr LSize Origin Snap% Move Log Copy% Convert
lvol0 server4 -wi-ao 50.00g
root server4 -wi-ao 40.00g
swap_1 server4 -wi-ao 4.00g
$ sudo vgs
VG #PV #LV #SN Attr VSize VFree
server4 1 3 0 wz--n- 135.73g 1.73 g
$ sudo e2fsck -f /dev/server4/lvol0
$ sudo lvresize /dev/server4/lvol0 -L 50G --resizefs
fsck from util-linux 2.20.1
e2fsck 1.42 (29-Nov-2011)
/dev/mapper/server4-lvol0: clean, 3754/2621440 files, 3140894/10485760 blocks
resize2fs 1.42 (29-Nov-2011)
Resizing the filesystem on /dev/dm-2 to 13107200 (4k) blocks.
The filesystem on /dev/dm-2 is now 13107200 blocks long.
Reducing logical volume lvol0 to 50.00 GiB
Logical volume lvol0 successfully resized
Re-mount your device in the OSD directory and launch the OSD daemon:
$ sudo mount -a
$ sudo service ceph osd1 start
Check the status ceph -w, you should noticed that the size changed and that everything is back to normal.
II.6. Adjust the replication level
The replication level is set to 2 by default, you can easily check this with the size 2 value:
$ ceph osd dump | grep ^pool
pool 0 'data' rep size 2 crush_ruleset 0 object_hash rjenkins pg_num 192 pgp_num 192 last_change 1 owner 0 crash_replay_interval 45
pool 1 'metadata' rep size 2 crush_ruleset 1 object_hash rjenkins pg_num 192 pgp_num 192 last_change 1 owner 0
pool 2 'rbd' rep size 2 crush_ruleset 2 object_hash rjenkins pg_num 192 pgp_num 192 last_change 1 owner 0
pool 3 'nova' rep size 2 crush_ruleset 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 22 owner 0
pool 4 'images' rep size 2 crush_ruleset 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 10 owner 0
Of course each pool might store more critical data, for instance my pool called nova store the RBD volume of each virtual machine, so I increased the replication level like this:
$ ceph osd pool set nova size 3
set pool 3 size to 3
II.7. Connect your client
Clients can access the RADOS cluster either directly via librados with rados command. The usage of librbd is possible as well with the RBD tool (via rbd command), which creates an image / volume abstraction over the object store. To achieve highly available monitor, simply put all of them in the mount option:
$ ceph-authtool --print-key /etc/ceph/keyring.admin
AQARB71PUCuuAxAAPhlUGzkRdDdjNDJy1w8MQQ==
client:~$ sudo mount -t ceph 172.17.1.4:6789,172.17.1.5:6789,172.17.1.7:6789:/ /mnt/ -vv -o name=admin,secret=AQDVGc5P0LXzJhAA5C019tbdrgypFNXUpG2cqQ==
parsing options: rw,name=admin,secret=AQDVGc5P0LXzJhAA5C019tbdrgypFNXUpG2cqQ==
Monitor reliability?
I tried to simulate a MON failure while CephFS is mounted. I stopped one of my MON server but precisely the one used for mounting CephFS. Oh yes.. I forgot to tell you I used only one monitor to mount Ceph… And the result was really unexpected, after I stopped the monitor the CephFS didn’t crashed and stayed alive :). There is some magic performed under the hood by Ceph. I don’t really know how but Ceph and monitors are clever enough to figure out MON failure and re-initiate a connection to an another monitor and thus keep the the mounting filesystem alive.
Check this:
client:~$ mount | grep ceph
client:~$ sudo mount -t ceph 172.17.1.7:6789:/ /mnt -vv -o name=admin,secret=AQDVGc5P0LXzJhAA5C019tbdrgypFNXUpG2cqQ==
client:~$ mount grep ceph
172.17.1.7:6789:/ on /mnt type ceph (rw,name=admin,secret=AQDVGc5P0LXzJhAA5C019tbdrgypFNXUpG2cqQ==)
client:~$ ls /mnt/
client:~$ touch /mnt/mon-ok
client:~$ ls /mnt/
mon-ok
client:~$ sudo netstat -plantu | grep EST | grep 6789
tcp 0 0 172.17.1.2:60462 172.17.1.7:6789 ESTABLISHED -
server6:~$ sudo service ceph stop mon
=== mon.2 ===
Stopping Ceph mon.2 on server6...kill 532...done
client:~$ touch /mnt/mon-3-down
client:~$ sudo netstat -plantu | grep EST | grep 6789
tcp 0 0 172.17.1.2:60462 172.17.1.5:6789 ESTABLISHED -
server6:~$ sudo service ceph start mon
=== mon.2 ===
Starting Ceph mon.2 on server6...
starting mon.2 rank 2 at 172.17.1.7:6789/0 mon_data /srv/ceph/mon2 fsid caf6e927-e87e-4295-ab01-3799d6e24be1
server4:~$ sudo service ceph stop mon
=== mon.1 ===
Stopping Ceph mon.1 on server4...kill 4049...done
client:~$ touch /mnt/mon-2-down
client:~$ sudo netstat -plantu | grep EST | grep 6789
tcp 0 0 172.17.1.2:60462 172.17.1.4:6789 ESTABLISHED -
client:~$ touch /mnt/mon-2-down
client:~$ ls /mnt/
mon-ok mon-3-down mon-2-down
Impressive!
III. Openstack integration
III.1. RDB and nova-volume
Before starting, here is my setup, I volontary installed nova-volume on a node of my Ceph cluster:
--- - ceph-node-01
|
- nova-volume
--- - ceph-node-02
--- - ceph-node-03
According to the OpenStack documentation on RBD I just added those lines in nova.conf:
--volume_driver=nova.volume.driver.RBDDriver
--rbd_pool=nova
By default, the RBD pool named rbd will be use by OpenStack if nothing is specified. I prefered to use nova as a pool, so I created it:
$ rados lspools
data
metadata
rbd
$ rados mkpool nova
$ rados lspools
data
metadata
rbd
nova
$ rbd --pool nova ls
volume-0000000c
$ rbd --pool nova info volume-0000000c
rbd image 'volume-0000000c':
size 1024 MB in 256 objects
order 22 (4096 KB objects)
block_name_prefix: rb.0.0
parent: (pool -1)
Restart your nova-volume:
$ sudo service nova-volume restart
Try to create a volume, you shouldn’t have any problem :)
$ nova volume-create --display_name=rbd-vol 1
Check this via:
$ nova volume-list
+----+-----------+--------------+------+-------------+-------------+
| ID | Status | Display Name | Size | Volume Type | Attached to |
+----+-----------+--------------+------+-------------+-------------+
| 51 | available | rbd-vol | 1 | None | |
+----+-----------+--------------+------+-------------+-------------+
Check in RBD:
$ rbd --pool nova ls
volume-00000033
$ rbd --pool nova info volume-00000033
rbd image 'volume-00000033':
size 1024 MB in 256 objects
order 22 (4096 KB objects)
block_name_prefix: rb.0.3
parent: (pool -1)
Everything looks great, but wait.. can I attach it to an instance?
Since we are using cephx authentication, nova and libvirt require a couple more steps.
For security and clarity purpose you may want to create a new user and give it access to your Ceph cluster with fine permissions. Let’s say that you want to use a user called nova, each connection to your MON server will be initiate as client.nova instead of client.admin. This behavior is define by the rados_create function which create a handle for communicating with your RADOS cluster. Ceph environment variables are read when this is called, so if $CEPH_ARGS specifies everything you need to connect, no further configuration is necessary. The trick is to add the following lines at the beginning of the /usr/lib/python2.7/dist-packages/nova/volume/driver.py file:
# use client.nova instead of nova.admin
import os
os.environ["CEPH_ARGS"] = "--id nova"
Adding the variable via the init script of nova-volume should also work, it’s up to you. The nova user needs this environment variable.
Here I assume that you use client.admin, if you use client.nova change every values called admin to nova. Now we can start to configure the secret in libvirt, create a file secret.xml and add this content:
<secret ephemeral='no' private='no'>
<usage type='ceph'>
<name>client.admin secret</name>
</usage>
</secret>
Import it into virsh:
$ sudo virsh secret-define --file secret.xml
Secret 83a0e970-a18b-5490-6fce-642f9052f976 created
Virsh tells you the UUID of the secret, which is how you reference it for other libvirt commands. Now set this value with the client.admin key:
$ sudo virsh secret-set-value --secret 83a0e970-a18b-5490-6fce-642f9052f976 --base64 AQDVGc5P0LXzJhAA5C019tbdrgypFNXUpG2cqQ==
Secret value set
At this point you should be able to attach a disk manually with virsh using this disk.xml file. I used the RBD volume previously created:
<disk type='network'>
<driver name="qemu" type="raw"/>
<source protocol="rbd" name="nova/volume-00000033">
<host name='172.17.1.4' port='6789'/>
<host name='172.17.1.5' port='6789'/>
<host name='172.17.1.7' port='6789'/>
</source>
<target dev="vdb" bus="virtio"/>
<auth username='admin'>
<secret type='ceph' uuid='83a0e970-a18b-5490-6fce-642f9052f976'/>
</auth>
</disk>
Some explanations about this file:
nameargument in<source>corresponds to the pool and the volume:name="your-pool/your-volume".- This line
<host name='172.17.1.4' port='6789'/>points to a Ceph monitor server.
The xml syntax is documented on the libvirt website.
Login to your compute node where the instance is running and check the id of the running instance. If you don’t know where the instance is running launch the following commands:
$ nova list
+--------------------------------------+-------------------+--------+---------------------+
| ID | Name | Status | Networks |
+--------------------------------------+-------------------+--------+---------------------+
| e1457eea-ef67-4df3-8ba4-245d104d2b11 | instance-over-rbd | ACTIVE | vlan1=192.168.22.36 |
+--------------------------------------+-------------------+--------+---------------------+
$ nova show e1457eea-ef67-4df3-8ba4-245d104d2b11
+-------------------------------------+----------------------------------------------------------+
| Property | Value |
+-------------------------------------+----------------------------------------------------------+
| OS-DCF:diskConfig | MANUAL |
| OS-EXT-SRV-ATTR:host | server-02 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | None |
| OS-EXT-SRV-ATTR:instance_name | instance-000000d6 |
| OS-EXT-STS:power_state | 1 |
| OS-EXT-STS:task_state | None |
| OS-EXT-STS:vm_state | active |
| accessIPv4 | |
| accessIPv6 | |
| config_drive | |
| created | 2012-06-07T12:25:48Z |
| flavor | m1.tiny |
| hostId | 30dec431592ca96c90bb4990d0df235f4face63907a7fc2ecdcb36d3 |
| id | e1457eea-ef67-4df3-8ba4-245d104d2b11 |
| image | precise-ceph |
| key_name | seb |
| metadata | {} |
| name | instance-over-rbd |
| progress | 0 |
| status | ACTIVE |
| tenant_id | d1f5d27ccf594cdbb034c8a4123494e9 |
| updated | 2012-06-07T13:06:43Z |
| user_id | 557273155f8243bca38f77dcdca82ff6 |
| vlan1 network | 192.168.22.36 |
+-------------------------------------+----------------------------------------------------------+
As you can see my instance is running on the server-02, pick up the id of your instance here instance-000000d6 in virsh. Attach it manually with virsh:
server-02:~$ sudo virsh attach-device instance-000000d6 rbd.xml
Device attached successfully
Now check inside your instance, for this use your credential and log into it via ssh. You will see a new device called vdb:
server-02:~$ ssh -i seb.pem ubuntu@192.168.22.36
ubuntu@instance-over-rbd:~$ sudo fdisk -l
Disk /dev/vda: 2147 MB, 2147483648 bytes
255 heads, 63 sectors/track, 261 cylinders, total 4194304 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Device Boot Start End Blocks Id System
/dev/vda1 * 16065 4192964 2088450 83 Linux
Disk /dev/vdb: 1073 MB, 1073741824 bytes
16 heads, 63 sectors/track, 2080 cylinders, total 2097152 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Disk /dev/vdb doesn't contain a valid partition table
Now you are ready to use it:
ubuntu@instance-over-rbd:~$ sudo mkfs.ext4 /dev/vdb
mke2fs 1.42 (29-Nov-2011)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
65536 inodes, 262144 blocks
13107 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=268435456
8 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: done
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
ubuntu@instance-over-rbd:~$ sudo mount /dev/vdb /mnt
ubuntu@instance-over-rbd:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 2.0G 668M 1.3G 35% /
udev 242M 12K 242M 1% /dev
tmpfs 99M 212K 99M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 246M 0 246M 0% /run/shm
/dev/vdb 1022M 47M 924M 5% /mnt
ubuntu@instance-over-rbd:~$ sudo touch /mnt/test
ubuntu@instance-over-rbd:~$ ls /mnt/
lost+found test
Last but not least, edit your nova.conf on each nova-compute server with the authentication value. It’s working without those options, since we added them manually to libvirt, but I think it good to tell them to nova. You will be able to attach a volume to an instance from the nova cli with nova volume-attach command and from the dashboard as well :D
--rbd_user=admin
--rbd_secret_uuid=83a0e970-a18b-5490-6fce-642f9052f976
Here we go!
$ nova volume-create --display_name=nova-rbd-vol 1
$ nova volume-list
+----+-----------+--------------+------+-------------+--------------------------------------+
| ID | Status | Display Name | Size | Volume Type | Attached to |
+----+-----------+--------------+------+-------------+--------------------------------------+
| 51 | available | rbd-vol | 1 | None | |
| 57 | available | nova-rbd-vol | 1 | None | |
+----+-----------+--------------+------+-------------+--------------------------------------+
$ nova volume-attach e1457eea-ef67-4df3-8ba4-245d104d2b11 57 /dev/vdd
$ nova volume-list
+----+-----------+--------------+------+-------------+--------------------------------------+
| ID | Status | Display Name | Size | Volume Type | Attached to |
+----+-----------+--------------+------+-------------+--------------------------------------+
| 51 | available | rbd-vol | 1 | None | |
| 57 | in-use | nova-rbd-vol | 1 | None | e1457eea-ef67-4df3-8ba4-245d104d2b11 |
+----+-----------+--------------+------+-------------+--------------------------------------+
The first disk is marked as available simply because it has been attached manually with virsh and not with nova. Have a look inside your virtual machine :)
Detach the manually attached disk:
$ sudo virsh detach-device instance-000000d6 rbd.xml
Device detached successfully
/!\ Important note, the secret.xml needs to be added on each nova-compute, more precisely to libvirt. Keep the first secret (uuid) and put it into your secret.xml. The file below becomes your new secret.xml reference file.
<secret ephemeral='no' private='no'>
<uuid>83a0e970-a18b-5490-6fce-642f9052f976</uuid>
<usage type='ceph'>
<name>client.admin secret</name>
</usage>
</secret>
Attaching error found:
error : qemuMonitorJSONCheckError:318 : internal error unable to execute QEMU command 'device_add': Device 'virtio-blk-pci' could not be initialized
error : qemuMonitorJSONCheckError:318 : internal error unable to execute QEMU command 'device_add': Duplicate ID 'virtio-disk2' for device
The first one occured when I tried to mount a volume with /dev/vdb as device name and the second occured with /dev/vdc. Solved by using a different device name than /dev/vdc/, I think libvirt remembers ‘somewhere’ and ‘somehow’ that a device was previously attached (the manually one). I didn’t really investigate since it can be simply solved.
EDIT: 11/07/2012
Some people reported tp me a common issue. There were unable to attach a RBD device with nova, but with libvirt it’s fine. If you have difficulties to make it working, you will probably need to update the libvirt AppArmor profile. If you check your /var/log/libvirt/qemu/your_instance_id.log, you should see:
unable to find any monitors in conf. please specify monitors via -m monaddr or -c ceph.conf
And if you dive into the debug mode:
debug : virJSONValueFromString:914 : string={"return": "error connecting\r\ncould not open disk image rbd:nova/volume-00000050: No such file or directory\r\n", "id": "libvirt-12"}
And of course it’s log in AppArmor and it’s pretty explicit:
$ sudo grep -i denied /var/log/kern.log
server-01 kernel: [28874.202700] type=1400 audit(1341957073.795:51): apparmor="DENIED" operation="open" parent=1 profile="libvirt-bd261aa7-728b-4edb-bd18-2ae2370b6549" name="/etc/ceph/ceph.conf" pid=5833 comm="kvm" requested_mask="r" denied_mask="r" fsuid=108 ouid=0
Now edit the libvirt AppArmor profile, you need to adjust access controls for all VMs, new or existing:
$ sudo echo "/etc/ceph/** r," | sudo tee -a /etc/apparmor.d/abstractions/libvirt-qemu
$ sudo service libvirt-bin restart
$ sudo service apparmor reload
That’s all, after this libvirt/qemu will be able to read your ceph.conf and your keyring (if you use cephx) ;-).
III.2. RBD and Glance
III.2.1. RBD as Glance storage backend
I followed the official instructions from OpenStack documentation. I recommend to follow the upstream package from Ceph since the Ubuntu repo doesn’t provide a valid version. This issue has been recently reported by Florian Haas in the OpenStack and Ceph mailing list however the bug has already been tracked here. It has been uploaded to precise-proposed for SRU review and waiting for approval, this shouldn’t be too long. Be sure to add the Ceph repo (deb http://ceph.com/debian/ precise main) on your Glance server (as I did earlier).
$ sudo apt-get install python-ceph
Modify your glance-api.conf like so:
# Set the rbd storage
default_store = rbd
# ============ RBD Store Options =============================
# Ceph configuration file path
# If using cephx authentication, this file should
# include a reference to the right keyring
# in a client.<USER> section
rbd_store_ceph_conf = /etc/ceph/ceph.conf
# RADOS user to authenticate as (only applicable if using cephx)
rbd_store_user = glance
# RADOS pool in which images are stored
rbd_store_pool = images
# Images will be chunked into objects of this size (in megabytes).
# For best performance, this should be a power of two
rbd_store_chunk_size = 8
According to the glance configuration, I created a new pool and a new user for RADOS:
$ rados mkpool images
successfully created pool images
$ ceph-authtool --create-keyring /etc/glance/rbd.keyring
creating rbd.keyring
$ ceph-authtool --gen-key --name client.glance --cap mon 'allow r' --cap osd 'allow rwx pool=images' /etc/glance/rbd.keyring
$ ceph auth add client.glance -i /etc/glance/rbd.keyring
2012-05-24 10:45:58.101925 7f7097c31780 -1 read 122 bytes from /etc/glance/rbd.keyring
added key for client.glance
$ sudo chown glance:glance /etc/glance/rbd.keyring
After this you should see a new key in ceph:
$ ceph auth list
installed auth entries:
mon.
key: AQDVGc5PaLVfKBAAqWFONvImdw7WSu4Sf/e4qg==
mds.0
key: AQDPGc5PGGXXNxAAoMr9ebDaCwhWo+xbv7cm7A==
caps: [mds] allow
caps: [mon] allow rwx
caps: [osd] allow *
mds.1
key: AQC6Gc5PGK4cJxAAxRnNC0rRNGPqpJd3lNYWNA==
caps: [mds] allow
caps: [mon] allow rwx
caps: [osd] allow *
mds.2
key: AQDUGc5PWBRiHRAAUMp2s78p1C31Q0D8MjZS+Q==
caps: [mds] allow
caps: [mon] allow rwx
caps: [osd] allow *
osd.0
key: AQDJGc5PiGvTCxAAlV4WvTTeGgI2SpR7Vl2V2g==
caps: [mon] allow rwx
caps: [osd] allow *
osd.1
key: AQC0Gc5PoDLwGRAAjVvMaLhklPfzSfN1K91xOA==
caps: [mon] allow rwx
caps: [osd] allow *
osd.2
key: AQDOGc5PgDhwLBAAxuwS9w5d3nlVsm6ACMZJ2g==
caps: [mon] allow rwx
caps: [osd] allow *
client.admin
key: AQDVGc5P0LXzJhAA5C019tbdrgypFNXUpG2cqQ==
caps: [mds] allow
caps: [mon] allow *
caps: [osd] allow *
client.glance
key: AQDeJc5PwDqpCxAAdggTbAVxTDxGLqjTV5pJdg==
caps: [mon] allow r
caps: [osd] allow rwx pool=images
Now restart your glance server:
$ sudo service glance-api restart && sudo service glance-registry restart
Before uploading check your images pools:
$ rados --pool=images ls
rbd_directory
rbd_info
Try to upload a new image.
$ wget http://cloud-images.ubuntu.com/precise/current/precise-server-cloudimg-amd64-disk1.img
$ glance add name="precise-ceph" is_public=True disk_format=qcow2 container_format=ovf architecture=x86_64 < precise-server-cloudimg-amd64-disk1.img
Uploading image 'precise-ceph'
======================================================================================================[100%] 26.2M/s, ETA 0h 0m 0s
Added new image with ID: 70685ad4-b970-49b7-8bde-83e58b255d95
Check in glance:
$ glance index
ID Name Disk Format Container Format Size
------------------------------------ ------------------------------ -------------------- -------------------- --------------
60beab84-81a7-46d1-bb4a-19947937dfe3 precise-ceph qcow2 ovf 227213312
Recheck your images pool, oh! objects :D
$ rados --pool=images ls
rb.0.2.000000000001
rb.0.2.000000000004
rb.0.2.000000000008
rb.0.2.000000000006
rb.0.2.00000000000d
rb.0.2.00000000000e
rb.0.2.000000000011
rb.0.2.00000000000b
rb.0.2.000000000016
rb.0.2.000000000017
rb.0.2.000000000010
rb.0.2.000000000018
rb.0.2.000000000015
rb.0.2.000000000019
rb.0.2.00000000000c
rb.0.2.00000000001a
rb.0.2.00000000000f
rb.0.2.00000000001b
rb.0.2.000000000000
rb.0.2.000000000003
rb.0.2.000000000012
rb.0.2.00000000000a
rb.0.2.000000000013
60beab84-81a7-46d1-bb4a-19947937dfe3.rbd
rbd_directory
rb.0.2.000000000009
rb.0.2.000000000007
rb.0.2.000000000005
rb.0.2.000000000014
rbd_info
rb.0.2.000000000002
Size of the pool:
$ du precise-server-cloudimg-amd64.img
221888 precise-server-cloudimg-amd64.img
$ rados --pool=images df
pool name category KB objects clones degraded unfound rd rd KB wr wr KB
images - 221889 31 0 0 0 11 9 326 1333327
total used 24569260 2267
total avail 259342756
total space 298878748
Check the image in the glance database:
mysql> use glance;
mysql> select * from images where status='active' \G;
*************************** 1. row ***************************
id: cc7167d6-6dbe-4a2b-8609-b599a48ebbb6
name: precise-cephAAA
size: 227213312
status: active
is_public: 1
location: rbd://cc7167d6-6dbe-4a2b-8609-b599a48ebbb6
created_at: 2012-06-04 15:29:22
updated_at: 2012-06-04 15:29:31
deleted_at: NULL
deleted: 0
disk_format: qcow2
container_format: ovf
checksum: fa7325f35ab884c6598154dcd4548063
owner: d1f5d27ccf594cdbb034c8a4123494e9
min_disk: 0
min_ram: 0
protected: 0
As you can see, it’s stored in RBD: rbd://cc7167d6-6dbe-4a2b-8609-b599a48ebbb6
From now, you should be able to launch new instance, Glance will retrieve image from the RBD pool.
###III.2.2. Instance snapshot to RBD
Testing the snapshots:
instance ad0e6a24-9648-406f-b86d-6312ea905888: snapshotting
sudo nova-rootwrap qemu-img snapshot -c 56642cf3d09b49a7aa400b6bc07494b9 /var/lib/nova/instances/instance-00000097/disk
qemu-img convert -f qcow2 -O qcow2 -s 56642cf3d09b49a7aa400b6bc07494b9 /var/lib/nova/instances/instance-00000097/disk /tmp/tmpt7EriB/56642cf3d09b49a7aa400b6bc07494b9
sudo nova-rootwrap qemu-img snapshot -d 56642cf3d09b49a7aa400b6bc07494b9 /var/lib/nova/instances/instance-00000097/disk
Let’s describe the process:
- The first command initiates and create the snapshot with name
56642cf3d09b49a7aa400b6bc07494b9from the image disk of the instance located here/var/lib/nova/instances/instance-00000097/disk. - The second command will convert the image from qcow2 to qcow2 and store the backup into Glance thus in RBD. Here the image is stored as
qcow2format, this is not really what we want! I want to store an RBD (format) image. - The third command deletes the local file of the snapshot, no longer needed since the image has been stored in the Glance backend.
When you attempt to perform a snapshot of an instance from the dashboard or via the nova image-create command, nova executes a local copy of changes in a qcow2 file, however this file will be stored in Glance.
If you want to run a RBD snapshot through OpenStack, you need to take a volume snapshot. These functionnality is not exposed in the dashboard yet.
Snapshot a RBD volume:
snapshot snapshot-00000004: creating
snapshot snapshot-00000004: creating from (pid=18829) create_snapshot
rbd --pool nova snap create --snap snapshot-00000004 volume-00000042
snapshot snapshot-00000004: created successfully from (pid=18829) create_snapshot
Verify:
$ rbd --pool=nova snap ls volume-00000042
2 snapshot-00000004 1073741824
Full RBD managment?
$ qemu-img info precise-server-cloudimg-amd64.img
image: precise-server-cloudimg-amd64.img
file format: qcow2
virtual size: 2.0G (2147483648 bytes)
disk size: 217M
cluster_size: 65536
$ sudo qemu-img convert -f qcow2 -O rbd precise-server-cloudimg-amd64.img rbd:images/glance
$ qemu-img info rbd:nova/ceph-img-cli
image: rbd:nova/ceph-img-cli
file format: raw
virtual size: 2.0G (2147483648 bytes)
disk size: unavailable
There is a surprising value here, why does the image appear as raw format? And why does the file size become unavailable? For those of you, you want to go further with Qemu-RBD snapshot, see the documentation from Ceph
III.3. Does the dream come true?
Boot from a RBD image? I uploaded a new image in the glance RBD backend and try to boot with this image and it works. Glance is able to retrieve images over the RBD backend configured. You will usually see this log message:
INFO nova.virt.libvirt.connection [-] [instance: ce230d11-ddf8-4298-a7d9-40ae8690ff11] Instance spawned successfully.
III.4. Boot from a volume
Booting from a volume will require specifying a dummy image id, as shown in these scripts:
#!/bin/bash
set -e
DIR=`dirname $0`
if [ ! -f $DIR/debian.img ]; then
echo "Downloading debian image..."
wget http://ceph.newdream.net/qa/debian.img -O $DIR/debian.img
fi
touch $DIR/dummy_img
glance add name="dummy_raw_img" is_public=True disk_format=rawi container_format=ovf architecture=x86_64 < dummy_img
echo "Waiting for image to become available..."
while true; do
if ( timeout 5 nova image-list | egrep -q 'dummy_raw_img|ACTIVE' ) then
break
fi
sleep 2
done
echo "Creating volume..."
nova volume-create --display_name=dummy 1
echo "Waiting for volume to be available..."
while true; do
if ( nova volume-list | egrep -q 'dummy|available' ) then
break
fi
sleep 2
done
echo "Replacing blank image with real one..."
# last created volume id, assuming pool nova
DUMMY_VOLUME_ID=$(rbd --pool=nova ls | sed -n '$p')
rbd -p nova rm $VOLUME_ID
rbd -p nova import $DIR/debian.img $DUMMY_VOLUME_ID
echo "Requesting an instance..."
$DIR/boot-from-volume
echo "Waiting for instance to start..."
while true; do
if ( nova list | egrep -q "boot-from-rbd|ACTIVE" ) then
break
fi
sleep 2
done
#!/usr/bin/env python
import argparse
import httplib2
import json
import os
def main():
http = httplib2.Http()
parser = argparse.ArgumentParser(description='Boot an OpenStack instance from RBD')
parser.add_argument(
'--endpoint',
help='the Nova API endpoint (http://IP:port/vX.Y/)',
default=os.getenv("http://172.17.1.6:8774/v2/"),
)
parser.add_argument(
'--image-id',
help="The image ID Nova will pretend to boot from (ie, 1 -- not ami-0000001)",
default=4,
)
parser.add_argument(
'--volume-id',
help='The RBD volume ID (ie, 1 -- not volume-0000001)',
default=1,
)
parser.add_argument(
'-v', '--verbose',
action='store_true',
default=False,
help='be more verbose',
)
args = parser.parse_args()
headers = {
'Content-Type': 'application/json',
'x-auth-project-id': 'admin',
'x-auth-token': 'admin:admin',
'Accept': 'application/json',
}
req = {
'server':
{
'min_count': 1,
'flavorRef': 1,
'name': 'test1',
'imageRef': args.image_id,
'max_count': 1,
'block_device_mapping': [{
'virtual': 'root',
'device_name': '/dev/vda',
'volume_id': args.volume_id,
'delete_on_termination': False,
}]
}}
resp, body = http.request(
'{endpoint}/volumes/os-volumes_boot'.format(endpoint=args.endpoint),
method='POST',
headers=headers,
body=json.dumps(req),
)
if resp.status == 200:
print "Instance scheduled successfully."
if args.verbose:
print json.dumps(json.loads(body), indent=4, sort_keys=True)
else:
print "Failed to create an instance: response status", resp.status
print json.dumps(json.loads(body), indent=4, sort_keys=True)
if __name__ == '__main__':
main()
Both are a little bit deprecated so I re-wrote some parts, it’s not that demanding. I barely spent much time on it, so there’s still work to be done. For example, I don’t use euca API, so I simply re-wrote according to nova-api.
Josh Durgin from Inktank said the following:
What’s missing is that OpenStack doesn’t yet have the ability to initialize a volume from an image. You have to put an image on one yourself before you can boot from it currently. This should be fixed in the next version of OpenStack. Booting off of RBD is nice because you can do live migration, although I haven’t tested that with OpenStack, just with libvirt. For Folsom, we hope to have copy-on-write cloning of images as well, so you can store images in RBD with glance, and provision instances booting off cloned RBD volumes in very little time.
It’s already in the Folsom’s roadmap
I quickly tried this manipulation, but without success:
$ nova volume-create --display_name=dummy 1
$ nova volume-list
+----+-----------+--------------+------+-------------+--------------------------------------+
| ID | Status | Display Name | Size | Volume Type | Attached to |
+----+-----------+--------------+------+-------------+--------------------------------------+
| 69 | available | dummy | 2 | None | |
+----+-----------+--------------+------+-------------+--------------------------------------+
$ rbd -p nova ls
volume-00000045
$ rbd import debian.img volume-00000045
Importing image: 13% complete...2012-06-08 13:45:34.562112 7fbb19835700 0 client.4355.objecter pinging osd that serves lingering tid 1 (osd.1)
Importing image: 27% complete...2012-06-08 13:45:39.563358 7fbb19835700 0 client.4355.objecter pinging osd that serves lingering tid 1 (osd.1)
Importing image: 41% complete...2012-06-08 13:45:44.563607 7fbb19835700 0 client.4355.objecter pinging osd that serves lingering tid 1 (osd.1)
Importing image: 55% complete...2012-06-08 13:45:49.564244 7fbb19835700 0 client.4355.objecter pinging osd that serves lingering tid 1 (osd.1)
Importing image: 69% complete...2012-06-08 13:45:54.565737 7fbb19835700 0 client.4355.objecter pinging osd that serves lingering tid 1 (osd.1)
Importing image: 83% complete...2012-06-08 13:45:59.565893 7fbb19835700 0 client.4355.objecter pinging osd that serves lingering tid 1 (osd.1)
Importing image: 97% complete...2012-06-08 13:46:04.567426 7fbb19835700 0 client.4355.objecter pinging osd that serves lingering tid 1 (osd.1)
Importing image: 100% complete...done.
$ nova boot --flavor m1.tiny --image precise-ceph --block_device_mapping vda=69:::0 --security_groups=default boot-from-rbd
III.5. Live migration with CephFS!
I was brave enough to also experimented the live migration with the Ceph Filesystem. Some of these pre-requites are obvious but just to be sure, with the live-migration comes mandatory requirements as:
- 2 compute nodes
- a distributed file system, here CephFS
For the live-migration configuration I followed the official OpenStack documentation. The following actions need to be performed on each compute node:
Update the libvirt configurations. Modify /etc/libvirt/libvirtd.conf:
listen_tls = 0
listen_tcp = 1
auth_tcp = "none"
Modify /etc/init/libvirt-bin.conf and add the -l option:
libvirtd_opts=" -d -l"
Restart libvirt. After executing the command, ensure that libvirt is succesfully restarted.
$ sudo stop libvirt-bin && sudo start libvirt-bin
$ ps -ef | grep libvirt
Make sure that you see the -l flag in the ps command. You should be able to retrieve the information (passwordless) from an hypervisor to another, to test it simply run:
server-02:/$ sudo virsh --connect qemu+tcp://server-01/system list
Id Name State
----------------------------------
1 instance-000000af running
3 instance-000000b5 running
My nova.conf options:
--live_migration_retry_count=30
--live_migration_uri=qemu+tcp://%s/system
--live_migration_bandwidth=0
Mount the nova instance directory with CephFS and assign nova as the owner of the directory:
$ sudo mount -t ceph 172.17.1.4:6789:/ /var/lib/nova/instances -vv -o name=admin,secret=AQARB71PUCuuAxAAPhlUGzkRdDdjNDJy1w8MQQ==
$ sudo chown nova:nova /var/lib/nova/instances
Check your nova services:
server-01:~$ sudo nova-manage service l
Binary Host Zone Status State Updated_At
nova-consoleauth server-05 nova enabled :-) 2012-05-29 15:34:15
nova-cert server-05 nova enabled :-) 2012-05-29 15:34:15
nova-scheduler server-05 nova enabled :-) 2012-05-29 15:34:14
nova-compute server-02 nova enabled :-) 2012-05-29 15:34:14
nova-network server-02 nova enabled :-) 2012-05-29 15:34:18
nova-volume server-03 nova enabled :-) 2012-05-29 15:34:23
nova-compute server-01 nova enabled :-) 2012-05-29 15:33:50
nova-network server-01 nova enabled :-) 2012-05-29 15:33:51
server-01:~$ nova list
+--------------------------------------+---------------+--------+----------------------------------+
| ID | Name | Status | Networks |
+--------------------------------------+---------------+--------+----------------------------------+
| 1ff0f8c4-bdc9-48d4-95ea-515f3a2ff6d4 | pouet | ACTIVE | vlan1=192.168.22.42, 172.17.1.43 |
| 5e7618a1-15df-45e8-86b6-02698e143b92 | boot-from-rbd | ACTIVE | vlan1=192.168.22.36 |
| ce230d11-ddf8-4298-a7d9-40ae8690ff11 | medium-rbd | ACTIVE | vlan1=192.168.22.39 |
| ea68ee9a-7b0b-48d7-a9ce-a9328077ca9d | test | ACTIVE | vlan1=192.168.22.41 |
+--------------------------------------+---------------+--------+----------------------------------+
server-01:~$ nova show ce230d11-ddf8-4298-a7d9-40ae8690ff11
+-------------------------------------+----------------------------------------------------------+
| Property | Value |
+-------------------------------------+----------------------------------------------------------+
| OS-DCF:diskConfig | MANUAL |
| OS-EXT-SRV-ATTR:host | server-01 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | None |
| OS-EXT-SRV-ATTR:instance_name | instance-000000b5 |
| OS-EXT-STS:power_state | 1 |
| OS-EXT-STS:task_state | None |
| OS-EXT-STS:vm_state | active |
| accessIPv4 | |
| accessIPv6 | |
| config_drive | |
| created | 2012-05-29T13:50:45Z |
| flavor | m1.medium |
| hostId | ec2890ed9e2f998820c4f767b66822c60910a293d0a63723177fff74 |
| id | ce230d11-ddf8-4298-a7d9-40ae8690ff11 |
| image | precise-cephA |
| key_name | seb |
| metadata | {} |
| name | medium-rbd |
| progress | 0 |
| status | ACTIVE |
| tenant_id | d1f5d27ccf594cdbb034c8a4123494e9 |
| updated | 2012-05-29T15:31:27Z |
| user_id | 557273155f8243bca38f77dcdca82ff6 |
| vlan1 network | 192.168.22.39 |
+-------------------------------------+----------------------------------------------------------+
server-01:~$ sudo virsh list
Id Name State
----------------------------------
1 instance-000000af running
3 instance-000000b5 running
Run the live-migration command in debug mode:
server-01:~$ nova --debug live-migration ce230d11-ddf8-4298-a7d9-40ae8690ff11 server-02
connect: (172.17.1.6, 5000)
send: 'POST /v2.0/tokens HTTP/1.1\r\nHost: 172.17.1.6:5000\r\nContent-Length: 100\r\ncontent-type: application/json\r\naccept-encoding: gzip, deflate\r\naccept: application/json\r\nuser-agent: python-novaclient\r\n\r\n{"auth": {"tenantName": "admin", "passwordCredentials": {"username": "admin", "password": "admin"}}}'
reply: 'HTTP/1.1 200 OK\r\n'
header: Content-Type: application/json
header: Vary: X-Auth-Token
header: Date: Tue, 29 May 2012 15:31:39 GMT
header: Transfer-Encoding: chunked
connect: (172.17.1.6, 8774)
send: u'GET /v2/d1f5d27ccf594cdbb034c8a4123494e9/servers/ce230d11-ddf8-4298-a7d9-40ae8690ff11 HTTP/1.1\r\nHost: 172.17.1.6:8774\r\nx-auth-project-id: admin\r\nx-auth-token: 8758eb02f8f24810a6c8f11c7434f0b1\r\naccept-encoding: gzip, deflate\r\naccept: application/json\r\nuser-agent: python-novaclient\r\n\r\n'
reply: 'HTTP/1.1 200 OK\r\n'
header: X-Compute-Request-Id: req-4043a2da-4ed1-4c2e-a9c5-b73e81bbfe99
header: Content-Type: application/json
header: Content-Length: 1377
header: Date: Tue, 29 May 2012 15:31:39 GMT
send: u'GET /v2/d1f5d27ccf594cdbb034c8a4123494e9/servers/ce230d11-ddf8-4298-a7d9-40ae8690ff11 HTTP/1.1\r\nHost: 172.17.1.6:8774\r\nx-auth-project-id: admin\r\nx-auth-token: 8758eb02f8f24810a6c8f11c7434f0b1\r\naccept-encoding: gzip, deflate\r\naccept: application/json\r\nuser-agent: python-novaclient\r\n\r\n'
reply: 'HTTP/1.1 200 OK\r\n'
header: X-Compute-Request-Id: req-b86ccd91-a0ea-4c0c-9523-0f0f3a0a3a86
header: Content-Type: application/json
header: Content-Length: 1377
header: Date: Tue, 29 May 2012 15:31:39 GMT
send: u'POST /v2/d1f5d27ccf594cdbb034c8a4123494e9/servers/ce230d11-ddf8-4298-a7d9-40ae8690ff11/action HTTP/1.1\r\nHost: 172.17.1.6:8774\r\nContent-Length: 92\r\nx-auth-project-id: admin\r\naccept-encoding: gzip, deflate\r\naccept: application/json\r\nx-auth-token: 8758eb02f8f24810a6c8f11c7434f0b1\r\nuser-agent: python-novaclient\r\ncontent-type: application/json\r\n\r\n{"os-migrateLive": {"disk_over_commit": false, "block_migration": false, "host": "server-02"}}'
reply: 'HTTP/1.1 202 Accepted\r\n'
header: Content-Type: text/html; charset=UTF-8
header: Content-Length: 0
header: Date: Tue, 29 May 2012 15:31:52 GMT
Sometimes you can get this message from the nova-scheduler logs:
Casted 'live_migration' to compute 'server-01' from (pid=10963) cast_to_compute_host /usr/lib/python2.7/dist-packages/nova/scheduler/driver.py:80
And somehow you must get something from the logs, so check:
- nova-compute logs
- nova-scheduler logs
- libvirt logs
The libvirt logs could show those errors:
error : virExecWithHook:328 : Cannot find 'pm-is-supported' in path: No such file or directory
error : virNetClientProgramDispatchError:174 : Unable to read from monitor: Connection reset by peer
The first issue (pm) was solved by installing this package:
$ sudo apt-get install pm-utils -y
The second one is a little bit more tricky, the only glue I found was to disable the VNC console according to this thread. Finally check the log and see:
instance: 962c222f-2280-43e9-83be-c27a31f77946] Migrating instance to server-02 finished successfully.
Sometimes this message doesn’t appear, but the live-migration successfully performed, the best check is to wait and watch on the distant server:
$ watch sudo virsh list
Every 2.0s: sudo virsh list
Id Name State
----------------------------------
Every 2.0s: sudo virsh list
Id Name State
----------------------------------
6 instance-000000dc shut off
Every 2.0s: sudo virsh list
Id Name State
----------------------------------
6 instance-000000dc paused
Every 2.0s: sudo virsh list
Id Name State
----------------------------------
6 instance-000000dc running
During the live migration, you should see those states in virsh:
- shut off
- paused
- running
That’s all! The downtime for m2.tiny instance was approximatively 3 sec.
III.6. Virtual instances disk’s errors - Solved!
When I use Ceph to store the /var/lib/nova/instances directory of each nova-compute server I have these I/O errors inside the virtual machines…
Buffer I/O error on device vda1, logical block 593914
Buffer I/O error on device vda1, logical block 593915
Buffer I/O error on device vda1, logical block 593916
EXT4-fs warning (device vda1): ext4_end_bio:251: I/O error writing to inode 31112 (offset 7852032 size 524288 starting block 595925)
JBD2: Detected IO errors while flushing file data on vda1-8
Logs from the kernel during the boot sequence of the instance:
server-01 kernel: [ 400.354943] nbd15: p1
server-01 kernel: [ 405.710253] EXT4-fs (dm-2): mounted filesystem with ordered data mode. Opts: (null)
server-01 kernel: [ 410.400054] block nbd15: NBD_DISCONNECT
server-01 kernel: [ 410.400190] block nbd15: Receive control failed (result -32)
server-01 kernel: [ 410.400656] block nbd15: queue cleared
This issue appears everytime I launched a new instance. Sometimes waiting for the ext4 auto mecanism recovery solve temporary the problem but the filesystem still stays unstable. This error is probably due to the ext4 filesystem. It happens really often and I don’t have any clue at the moment maybe a filesystem option or switching from ext4 to XFS will do the trick. At the moment I tried several mount options inside the VM like nobarrier or noatime but nothing changed. This is what I got when I tried to perform a basic operation like installing a package:
Reading package lists... Error!
E: Unable to synchronize mmap - msync (5: Input/output error)
E: The package lists or status file could not be parsed or opened.
This can be solved by the following commands but it’s neither useful nor relevant since this error will occur again and again…
$ sudo apt-get clean
$ sudo apt-get update
$ sudo apt-get install 'your_package'
Filesystem check on each Ceph node:
server6:~$ sudo service ceph stop osd
=== osd.2 ===
Stopping Ceph osd.2 on server6...kill 26140...done
server6:~$ sudo umount /srv/ceph/osd2/
server6:~$ sudo fsck.ext4 -fy /dev/server6/ceph-ext4
e2fsck 1.42 (29-Nov-2011)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/server6/ceph-ext4: 4567/1310720 files (58.0% non-contiguous), 3370935/5242880 blocks
ext4 check on the second server:
server4:~$ sudo fsck.ext4 -fy /dev/server4/lvol0
e2fsck 1.42 (29-Nov-2011)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/server4/lvol0: 3686/3276800 files (5.2% non-contiguous), 2935930/13107200 blocks
ext4 check on the third server:
server-003:~$ sudo fsck.ext4 -fy /dev/nova-volumes/lvol0
e2fsck 1.42 (29-Nov-2011)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
/lost+found not found. Create? yes
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/nova-volumes/lvol0: ***** FILE SYSTEM WAS MODIFIED *****
/dev/nova-volumes/lvol0: 3435/6553600 files (6.7% non-contiguous), 2783459/26214400 blocks
Nothing relevant, everything is properly working.
This issue is unsolved, it’s simply related to the fact that CephFS is not stable enough. It can’t handle this amount of I/O. A possible work around, here and here. I don’t even thing that using XFS instead of ext4 will change the outcome. It seems that this issue also occur with RBD volume, see on the ceph tracker.
According to this reported bug (and the mailing list discussion) this issue affects rbd volumes inside virtual machine, the workaround here is to active the rbd caching, an option should be added inside the xml file while attaching a device.
<source protocol='rbd' name='your-pool/your-volume:rbd_cache=true'>
I didn’t check this workaround yet, but it seems to be solved by enabling the cache.
UPDATE: 13/06/2012 - I/O ISSUES SOLVED
It seems that Ceph has a lot of difficulties with the direct I/O support, see below:
$ mount | grep ceph
172.17.1.4:6789,172.17.1.5:6789,172.17.1.7:6789:/ on /mnt type ceph (name=admin,key=client.admin)
$ dd if=/dev/zero of=/mnt/directio bs=8M count=1 oflag=direct
1+0 records in
1+0 records out
8388608 bytes (8.4 MB) copied, 0.36262 s, 23.1 MB/s
$ dd if=/dev/zero of=/mnt/directio bs=9M count=1 oflag=direct
dd: writing `/mnt/directio': Bad address
1+0 records in
0+0 records out
0 bytes (0 B) copied, 1.20184 s, 0.0 kB/s
This bug has been tracked on the Ceph tracker
It seems that Ceph doesn’t support the creation of blocks superior at 9M. And? And if you check your libvirt of an instance you will see this section:
<disk type='file' device='disk'>
<driver type='qcow2' cache='none'/>
<source file='/var/lib/nova/instances/instance-000000f9/disk'/>
<target dev='vda' bus='virtio'/>
</disk>
Setting the cache to none means using direct I/O… Note from the libvirt documentation:
The optional cache attribute controls the cache mechanism, possible values are “default”, “none”, “writethrough”, “writeback”, “directsync” (like “writethrough”, but it bypasses the host page cache) and “unsafe” (host may cache all disk io, and sync requests from guest are ignored). Since 0.6.0, “directsync” since 0.9.5, “unsafe” since 0.9.7
Cache parameters explained:
- none: uses O_DIRECT I/O that bypasses the filesystem cache on the host
- writethrough: uses O_SYNC I/O that is guaranteed to be commited to disk on return to userspace. Only cache read requests and immediately write to disk.
- writeback: uses normal buffered I/O that is written back later by the operating system. It caches the write requests in RAM, which bring high-performance but also increase the data loss probability.
Actually there is already a function to test if direct I/O are supported:
@staticmethod
def _supports_direct_io(dirpath):
testfile = os.path.join(dirpath, ".directio.test")
hasDirectIO = True
try:
f = os.open(testfile, os.O_CREAT | os.O_WRONLY | os.O_DIRECT)
os.close(f)
LOG.debug(_("Path '%(path)s' supports direct I/O") %
{'path': dirpath})
except OSError, e:
if e.errno == errno.EINVAL:
LOG.debug(_("Path '%(path)s' does not support direct I/O: "
"'%(ex)s'") % {'path': dirpath, 'ex': str(e)})
hasDirectIO = False
else:
LOG.error(_("Error on '%(path)s' while checking direct I/O: "
"'%(ex)s'") % {'path': dirpath, 'ex': str(e)})
raise e
except Exception, e:
LOG.error(_("Error on '%(path)s' while checking direct I/O: "
"'%(ex)s'") % {'path': dirpath, 'ex': str(e)})
raise e
finally:
try:
os.unlink(testfile)
except:
pass
return hasDirectIO
Somehow it’s not detected, mainly because the issue is related to the block size.
If direct I/O are supported it will specified in this file /usr/lib/python2.7/dist-packages/nova/virt/libvirt/connection.py, on line 1036:
@property
def disk_cachemode(self):
if self._disk_cachemode is None:
# We prefer 'none' for consistent performance, host crash
# safety & migration correctness by avoiding host page cache.
# Some filesystems (eg GlusterFS via FUSE) don't support
# O_DIRECT though. For those we fallback to 'writethrough'
# which gives host crash safety, and is safe for migration
# provided the filesystem is cache coherant (cluster filesystems
# typically are, but things like NFS are not).
self._disk_cachemode = "none"
if not self._supports_direct_io(FLAGS.instances_path):
self._disk_cachemode = "writethrough"
return self._disk_cachemode
The first trick was to modify this line:
self._disk_cachemode = "none"
With
self._disk_cachemode = "writethrough"
With this change, every instances will have the libvirt cache option set to writethrough even if the filesystem supports direct I/O.
Fix a corrumpted VM:
FSCKFIX=yes
Reboot the VM :)
Note: writeback is also supported with Ceph, it offers better performance than writethrough but writeback stays the safest way for your data. It depends on your need :)
IV. Benchmarks
Thoses benchmarks have been performed under ext4 filesystem and on 15K RPM hard drive disks.
IV.1. Rados builtin benchmark
IV.1.1. Cluster benchmark
$ uname -r
3.2.0-24-generic
$ ceph -v
ceph version 0.47.2 (commit:f5a9404445e2ed5ec2ee828aa53d73d4a002f7a5)
$ rados -p nova bench 100 write
Maintaining 16 concurrent writes of 4194304 bytes for at least 100 seconds.
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat
0 0 0 0 0 0 - 0
1 16 31 15 59.8134 60 0.988616 0.774045
2 16 46 30 59.8908 60 1.15953 0.835025
3 16 63 47 62.5881 68 0.914239 0.836658
4 16 76 60 59.9416 52 1.23871 0.906893
5 16 94 78 62.3493 72 0.92557 0.912052
6 16 113 97 64.6216 76 1.14571 0.914297
7 16 123 107 61.1052 40 1.08826 0.922949
8 16 138 122 60.9663 60 0.46168 0.969207
9 16 145 129 57.3044 28 1.0469 0.989164
10 16 166 150 59.972 84 1.50591 1.02505
11 16 186 170 61.7913 80 1.06359 0.99008
12 16 197 181 60.3086 44 1.45907 0.993509
13 16 212 196 60.2843 60 1.67142 1.01419
14 16 218 202 57.6929 24 1.57489 1.03316
15 16 223 207 55.1804 20 0.259759 1.03948
16 16 239 223 55.7307 64 1.81071 1.10588
17 16 253 237 55.7461 56 1.17068 1.10739
18 16 267 251 55.7598 56 1.15406 1.10697
19 16 280 264 55.5616 52 1.26379 1.10818
min lat: 0.124888 max lat: 2.50869 avg lat: 1.11042
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat
20 16 293 277 55.383 52 1.19662 1.11042
21 16 304 288 54.8409 44 1.21306 1.11133
22 16 324 308 55.9839 80 0.633551 1.11404
23 16 337 321 55.8104 52 0.155063 1.10398
24 16 350 334 55.6514 52 1.54921 1.1165
25 16 364 348 55.6651 56 1.26814 1.12392
26 16 367 351 53.9858 12 1.89539 1.13046
27 16 384 368 54.5045 68 1.13766 1.15098
28 16 398 382 54.5576 56 1.46389 1.14698
29 16 415 399 55.0208 68 1.03303 1.14274
30 16 431 415 55.3198 64 1.24156 1.14126
31 16 440 424 54.6965 36 1.19121 1.14321
32 16 457 441 55.1119 68 1.23561 1.14136
33 16 469 453 54.8963 48 1.21978 1.14207
34 16 486 470 55.2814 68 1.2799 1.13989
35 16 499 483 55.1874 52 0.233549 1.14
36 16 504 488 54.21 20 1.61804 1.14024
37 16 513 497 53.7178 36 2.10228 1.16011
38 16 527 511 53.7776 56 1.37356 1.17257
39 16 541 525 53.8344 56 1.40289 1.17057
min lat: 0.124888 max lat: 2.5194 avg lat: 1.17259
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat
40 16 553 537 53.6883 48 1.24732 1.17259
41 16 565 549 53.5494 48 1.5267 1.17512
42 16 578 562 53.5124 52 1.68045 1.17721
43 16 594 578 53.7561 64 0.279511 1.1751
44 16 608 592 53.8069 56 1.23636 1.1711
45 16 619 603 53.5888 44 1.56834 1.17327
46 16 633 617 53.6411 56 1.24921 1.1744
47 16 644 628 53.4359 44 0.228269 1.17318
48 16 654 638 53.1558 40 1.85967 1.18184
49 16 667 651 53.1321 52 1.11298 1.18894
50 16 679 663 53.0293 48 1.24697 1.19045
51 16 691 675 52.9306 48 1.41656 1.19212
52 16 704 688 52.9125 52 1.24629 1.19305
53 16 719 703 53.0461 60 1.23783 1.1931
54 16 740 724 53.6191 84 0.825043 1.18465
55 16 750 734 53.3714 40 1.12641 1.18158
56 16 766 750 53.561 64 1.58 1.18356
57 16 778 762 53.4634 48 1.33114 1.1805
58 16 779 763 52.6106 4 1.74222 1.18124
59 16 796 780 52.8713 68 2.13181 1.20095
min lat: 0.124888 max lat: 2.68683 avg lat: 1.20162
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat
60 16 805 789 52.59 36 1.36423 1.20162
61 16 817 801 52.5147 48 1.38829 1.20521
62 16 830 814 52.5063 52 1.26657 1.20691
63 16 845 829 52.6251 60 1.17306 1.20415
64 16 853 837 52.3028 32 1.73082 1.20619
65 16 864 848 52.175 44 1.99292 1.21222
66 16 880 864 52.354 64 1.09513 1.21345
67 16 892 876 52.2889 48 1.17609 1.21056
68 16 908 892 52.461 64 1.21753 1.21081
69 16 921 905 52.4542 52 1.07357 1.20978
70 16 936 920 52.5619 60 0.160182 1.20659
71 16 952 936 52.7229 64 0.251266 1.2015
72 16 965 949 52.7128 52 1.48819 1.20271
73 16 986 970 53.1412 84 0.940281 1.19764
74 16 994 978 52.8554 32 0.873665 1.19506
75 16 1000 984 52.4707 24 2.18796 1.20107
76 16 1012 996 52.4117 48 2.58551 1.21175
77 16 1029 1013 52.614 68 1.12385 1.20813
78 16 1042 1026 52.606 52 1.22075 1.20693
79 16 1056 1040 52.6489 56 0.285843 1.20635
min lat: 0.120974 max lat: 2.68683 avg lat: 1.20498
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat
80 16 1067 1051 52.5407 44 0.182956 1.20498
81 16 1076 1060 52.3365 36 1.74162 1.20995
82 16 1090 1074 52.3811 56 1.18474 1.21345
83 16 1103 1087 52.3764 52 1.45589 1.21301
84 16 1119 1103 52.5146 64 1.20541 1.20995
85 16 1134 1118 52.6026 60 1.27 1.20745
86 16 1145 1129 52.5025 44 0.173344 1.2067
87 16 1162 1146 52.6805 68 1.56221 1.20783
88 16 1174 1158 52.6273 48 0.12839 1.20479
89 16 1189 1173 52.71 60 1.27274 1.20651
90 16 1201 1185 52.6576 48 1.11873 1.20648
91 16 1211 1195 52.5185 40 1.32622 1.20716
92 16 1224 1208 52.5128 52 1.49926 1.21086
93 16 1234 1218 52.3782 40 0.163716 1.21123
94 16 1251 1235 52.5443 68 1.32683 1.2104
95 16 1264 1248 52.5385 52 1.01523 1.21017
96 16 1279 1263 52.6161 60 1.31704 1.20815
97 16 1294 1278 52.6921 60 1.45825 1.20717
98 16 1314 1298 52.9707 80 0.281634 1.2014
99 16 1325 1309 52.88 44 1.45331 1.20097
min lat: 0.120974 max lat: 2.68683 avg lat: 1.20099
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat
100 16 1340 1324 52.9511 60 1.43721 1.20099
101 2 1341 1339 53.0208 60 1.66956 1.20448
Total time run: 101.114344
Total writes made: 1341
Write size: 4194304
Bandwidth (MB/sec): 53.049
Average Latency: 1.20432
Max latency: 2.68683
Min latency: 0.120974
IV.1.2. OSD Benchmarks
From a console run:
$ for i in 0 1 2; do ceph osd tell $i bench; done
ok
ok
ok
Monitor the output from an another terminal:
$ ceph -w
osd.0 172.17.1.4:6802/22135 495 : [INF] bench: wrote 1024 MB in blocks of 4096 KB in 4.575725 sec at 223 MB/sec
osd.1 172.17.1.5:6801/8713 877 : [INF] bench: wrote 1024 MB in blocks of 4096 KB in 22.559266 sec at 46480 KB/sec
osd.2 172.17.1.7:6802/737 1274 : [INF] bench: wrote 1024 MB in blocks of 4096 KB in 20.011638 sec at 52398 KB/sec
As you can see, I have pretty bad performance on 2 OSDs. Both of them will bring down the performance of my whole cluster. (this statment will be verified bellow)
IV.2. Servers benchmarks
IV.2.1. server-03
server-03:~$ for ((i=0 ; 10 -$i ; i++)) ; do dd if=/dev/zero of=pouet bs=1000M count=1; rm pouet; done
1048576000 bytes (1.0 GB) copied, 2.23271 s, 470 MB/s
1048576000 bytes (1.0 GB) copied, 2.12575 s, 493 MB/s
1048576000 bytes (1.0 GB) copied, 2.12901 s, 493 MB/s
1048576000 bytes (1.0 GB) copied, 2.13956 s, 490 MB/s
1048576000 bytes (1.0 GB) copied, 2.14999 s, 488 MB/s
1048576000 bytes (1.0 GB) copied, 2.12281 s, 494 MB/s
1048576000 bytes (1.0 GB) copied, 2.12963 s, 492 MB/s
1048576000 bytes (1.0 GB) copied, 2.13597 s, 491 MB/s
1048576000 bytes (1.0 GB) copied, 2.14659 s, 488 MB/s
1048576000 bytes (1.0 GB) copied, 2.15181 s, 487 MB/s
Average: 488,6 MB/s
IV.2.2. server-04
server-04:~$ for ((i=0 ; 10 -$i ; i++)) ; do dd if=/dev/zero of=pouet bs=1000M count=1; rm pouet; done
1048576000 bytes (1.0 GB) copied, 4.676 s, 224 MB/s
1048576000 bytes (1.0 GB) copied, 4.62314 s, 227 MB/s
1048576000 bytes (1.0 GB) copied, 4.93966 s, 212 MB/s
1048576000 bytes (1.0 GB) copied, 10.5936 s, 99.0 MB/s
1048576000 bytes (1.0 GB) copied, 4.94419 s, 212 MB/s
1048576000 bytes (1.0 GB) copied, 4.70893 s, 223 MB/s
1048576000 bytes (1.0 GB) copied, 8.94163 s, 117 MB/s
1048576000 bytes (1.0 GB) copied, 4.79279 s, 219 MB/s
1048576000 bytes (1.0 GB) copied, 8.39481 s, 125 MB/s
1048576000 bytes (1.0 GB) copied, 8.97216 s, 117 MB/s
Average: 154,8 MB/s
IV.2.3. server-06
server-06:~$ for ((i=0 ; 10 -$i ; i++)) ; do dd if=/dev/zero of=pouet bs=1000M count=1; rm pouet; done
1048576000 bytes (1.0 GB) copied, 2.35758 s, 445 MB/s
1048576000 bytes (1.0 GB) copied, 2.37689 s, 441 MB/s
1048576000 bytes (1.0 GB) copied, 4.94374 s, 212 MB/s
1048576000 bytes (1.0 GB) copied, 2.55669 s, 410 MB/s
1048576000 bytes (1.0 GB) copied, 6.08993 s, 172 MB/s
1048576000 bytes (1.0 GB) copied, 2.2573 s, 465 MB/s
1048576000 bytes (1.0 GB) copied, 2.29013 s, 458 MB/s
1048576000 bytes (1.0 GB) copied, 5.67836 s, 185 MB/s
1048576000 bytes (1.0 GB) copied, 2.39934 s, 437 MB/s
1048576000 bytes (1.0 GB) copied, 5.87929 s, 178 MB/s
Average: 340,3 MB/s
IV.3. Bandwidth benchmarks
Quick bandwidth test between 2 servers:
server-03:~$ time dd if=/dev/zero of=test bs=2000M count=1; time scp test root@server-04:/dev/null;
2097152000 bytes (2.1 GB) copied, 4.46267 s, 470 MB/s
root@server-04's password:
test 100% 2000MB 52.6MB/s 00:47
real 0m49.298s
user 0m43.915s
sys 0m5.172s
It’s not really surprising since Ceph showed an average of 53MB/s. I clairly have a network bottlenck because all my servers are connected with GBit. I also test a copy from the root partition to the ceph shared mount directory to see how long does it take to write data into ceph:
$ time dd if=/dev/zero of=pouet bs=2000M count=1; time sudo cp pouet /var/lib/nova/instances/;
1+0 records in
1+0 records out
2097152000 bytes (2.1 GB) copied, 4.27012 s, 491 MB/s
real 0m4.465s
user 0m0.000s
sys 0m4.456s
real 0m5.778s
user 0m0.000s
sys 0m3.580s
Monitor from ceph:
16:24:01.943710 pg v11430: 592 pgs: 592 active+clean; 30471 MB data, 71127 MB used, 271 GB / 359 GB avail
16:24:04.129263 pg v11431: 592 pgs: 592 active+clean; 30591 MB data, 71359 MB used, 271 GB / 359 GB avail
16:24:06.187816 pg v11432: 592 pgs: 592 active+clean; 30691 MB data, 71632 MB used, 271 GB / 359 GB avail
16:24:07.345031 pg v11433: 592 pgs: 592 active+clean; 30815 MB data, 71932 MB used, 270 GB / 359 GB avail
16:24:08.283969 pg v11434: 592 pgs: 592 active+clean; 30967 MB data, 72649 MB used, 270 GB / 359 GB avail
16:24:11.458523 pg v11435: 592 pgs: 592 active+clean; 31079 MB data, 72855 MB used, 270 GB / 359 GB avail
16:24:12.543626 pg v11436: 592 pgs: 592 active+clean; 31147 MB data, 73007 MB used, 269 GB / 359 GB avail
16:24:15.447718 pg v11437: 592 pgs: 592 active+clean; 31195 MB data, 73208 MB used, 269 GB / 359 GB avail
16:24:18.258197 pg v11438: 592 pgs: 592 active+clean; 31319 MB data, 73260 MB used, 269 GB / 359 GB avail
16:24:23.187243 pg v11439: 592 pgs: 592 active+clean; 31467 MB data, 73488 MB used, 269 GB / 359 GB avail
16:24:24.680864 pg v11440: 592 pgs: 592 active+clean; 31574 MB data, 73792 MB used, 269 GB / 359 GB avail
16:24:25.299714 pg v11441: 592 pgs: 592 active+clean; 31622 MB data, 74013 MB used, 268 GB / 359 GB avail
16:24:27.015503 pg v11442: 592 pgs: 592 active+clean; 31626 MB data, 74101 MB used, 268 GB / 359 GB avail
16:24:28.554417 pg v11443: 592 pgs: 592 active+clean; 31810 MB data, 74237 MB used, 268 GB / 359 GB avail
16:24:32.029909 pg v11444: 592 pgs: 592 active+clean; 31827 MB data, 74333 MB used, 268 GB / 359 GB avail
16:24:32.814380 pg v11445: 592 pgs: 592 active+clean; 32231 MB data, 74586 MB used, 268 GB / 359 GB avail
16:24:33.803356 pg v11446: 592 pgs: 592 active+clean; 32291 MB data, 74900 MB used, 268 GB / 359 GB avail
16:24:36.476405 pg v11447: 592 pgs: 592 active+clean; 32291 MB data, 74938 MB used, 267 GB / 359 GB avail
16:24:37.674590 pg v11448: 592 pgs: 592 active+clean; 32292 MB data, 75054 MB used, 267 GB / 359 GB avail
16:24:38.711816 pg v11449: 592 pgs: 592 active+clean; 32292 MB data, 75108 MB used, 267 GB / 359 GB avail
The information reported by the -w option are asynchronous and not really significant. For instances we can’t tell that storing 2GB in Ceph DFS took 37 seconds.
IV.4. Instance benchmarks
Flavor details:
- CPU: 2
- RAM: 4GB
- Root partition: 10GB
ubuntu@instance-over-rbd:~$ for ((i=0 ; 10 -$i ; i++)) ; do dd if=/dev/zero of=pouet bs=1000M count=1; rm pouet; done
1048576000 bytes (1.0 GB) copied, 23.1742 s, 45.2 MB/s
1048576000 bytes (1.0 GB) copied, 33.765 s, 31.1 MB/s
1048576000 bytes (1.0 GB) copied, 39.409 s, 26.6 MB/s
1048576000 bytes (1.0 GB) copied, 22.8567 s, 45.9 MB/s
1048576000 bytes (1.0 GB) copied, 37.5275 s, 27.9 MB/s
1048576000 bytes (1.0 GB) copied, 18.422 s, 56.9 MB/s
1048576000 bytes (1.0 GB) copied, 20.1792 s, 52.0 MB/s
1048576000 bytes (1.0 GB) copied, 19.4536 s, 53.9 MB/s
1048576000 bytes (1.0 GB) copied, 15.5978 s, 67.2 MB/s
1048576000 bytes (1.0 GB) copied, 15.7292 s, 66.7 MB/s
Average: 47,34 MB/s
Benchmark your filesystem in order to detect I/O errors (ext4 oriented):
/*
* Copyright (C) 2010 Canonical
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
*
*/
/*
* Author Colin Ian King, colin.king@canonical.com
*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ioctl.h>
#include <linux/fs.h>
#include "fiemap.h"
#define FS_IOC_FIEMAP _IOWR('f', 11, struct fiemap)
void syntax(char **argv)
{
fprintf(stderr, "%s [filename]...\n",argv[0]);
}
struct fiemap *read_fiemap(int fd)
{
struct fiemap *fiemap;
int extents_size;
if ((fiemap = (struct fiemap*)malloc(sizeof(struct fiemap))) == NULL) {
fprintf(stderr, "Out of memory allocating fiemap\n");
return NULL;
}
memset(fiemap, 0, sizeof(struct fiemap));
fiemap->fm_start = 0;
fiemap->fm_length = 2*1024*1024; /* Lazy */
fiemap->fm_flags = 0;
fiemap->fm_extent_count = 0;
fiemap->fm_mapped_extents = 0;
/* Find out how many extents there are */
if (ioctl(fd, FS_IOC_FIEMAP, fiemap) < 0) {
fprintf(stderr, "fiemap ioctl() failed\n");
return NULL;
}
/* Read in the extents */
extents_size = sizeof(struct fiemap_extent) *
(fiemap->fm_mapped_extents);
/* Resize fiemap to allow us to read in the extents */
if ((fiemap = (struct fiemap*)realloc(fiemap,sizeof(struct fiemap) +
extents_size)) == NULL) {
fprintf(stderr, "Out of memory allocating fiemap\n");
return NULL;
}
memset(fiemap->fm_extents, 0, extents_size);
fiemap->fm_extent_count = fiemap->fm_mapped_extents;
fiemap->fm_mapped_extents = 0;
if (ioctl(fd, FS_IOC_FIEMAP, fiemap) < 0) {
fprintf(stderr, "fiemap ioctl() failed\n");
return NULL;
}
return fiemap;
}
void dump_fiemap(struct fiemap *fiemap, char *filename)
{
int i;
printf("File %s has %d extents:\n",filename, fiemap->fm_mapped_extents);
printf("#\tLogical Physical Length Flags\n");
for (i=0;i<fiemap->fm_mapped_extents;i++) {
printf("%d:\t%-16.16llx %-16.16llx %-16.16llx %-4.4x\n",
i,
fiemap->fm_extents[i].fe_logical,
fiemap->fm_extents[i].fe_physical,
fiemap->fm_extents[i].fe_length,
fiemap->fm_extents[i].fe_flags);
}
printf("\n");
}
int main(int argc, char **argv)
{
int i;
if (argc < 2) {
syntax(argv);
exit(EXIT_FAILURE);
}
for (i=1;i<argc;i++) {
int fd;
if ((fd = open(argv[i], O_RDONLY)) < 0) {
fprintf(stderr, "Cannot open file %s\n", argv[i]);
}
else {
struct fiemap *fiemap;
if ((fiemap = read_fiemap(fd)) != NULL)
dump_fiemap(fiemap, argv[i]);
close(fd);
}
}
exit(EXIT_SUCCESS);
}
---
Final results
Openstack + Ceph | |
Create RBD volume | |
Delete RBD volume | |
Snapshot RBD volume | |
Attaching RBD volume | |
Glance images storage backend (import) | |
Snapshot running instance to RBD | |
Booting from RBD | |
Booting from a snapshoted image | |
Boot VMs from shared /var/lib/nova/instances | |
Live migration with CephFS |
This table was created with Compare Ninja.
Observations
I hope I will be able to go further and use Ceph for production. Ceph seems fearly stable enough at the moment, for RBD and RADOS, CephFS doesn’t seem capable to handle huge I/O traffic. Also keep in mind that a company called Inktank offers a commercial support for Ceph, I don’t thing it’s a coincidence. Ceph will have a bright future. The recovery procedure is excellent, of course there is a lot of component which I would loved to play like fine crushmap tunning. This article could be updated at any time since I’m taking my research further :).
This article wouldn’t have been possible without the tremendous help of Josh Durgin from Inktank, many many thanks to him :)