
Here I’m going to setup high-availability features in our current infrastructure. I will add a new HAProxy node and will use pacemaker.
I. Introduction
In this article, the high-availability for the load-balancers is very critical. I’m going to use the existing infrastructure and set up pacemaker between the 2 HAProxy nodes. Pacemaker is the resource manager and corosync is the heartbeat (communication layer).
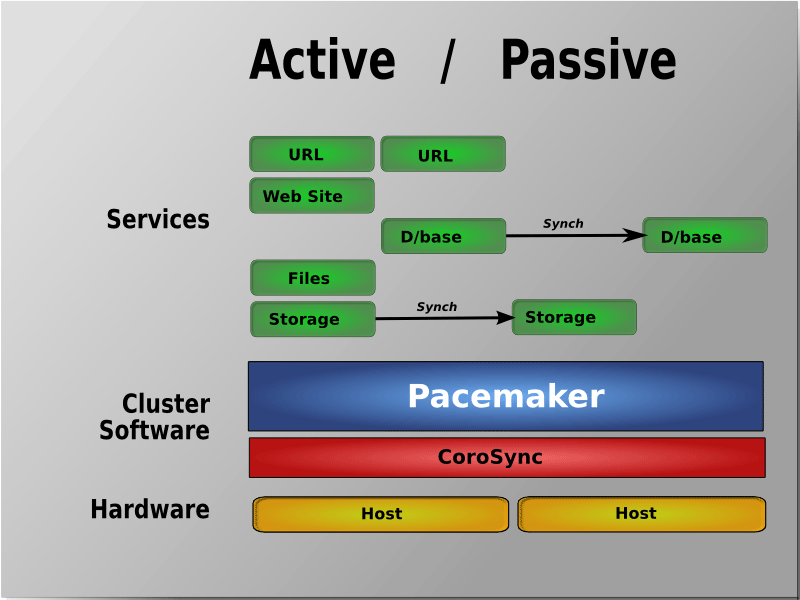
Reminder: the active/passive cluster consists in using 2 servers or more, only one node has the resource started. When the current owner of the ressource goes down, a failover is operate and the resource will be running on an another node.
II. Installation
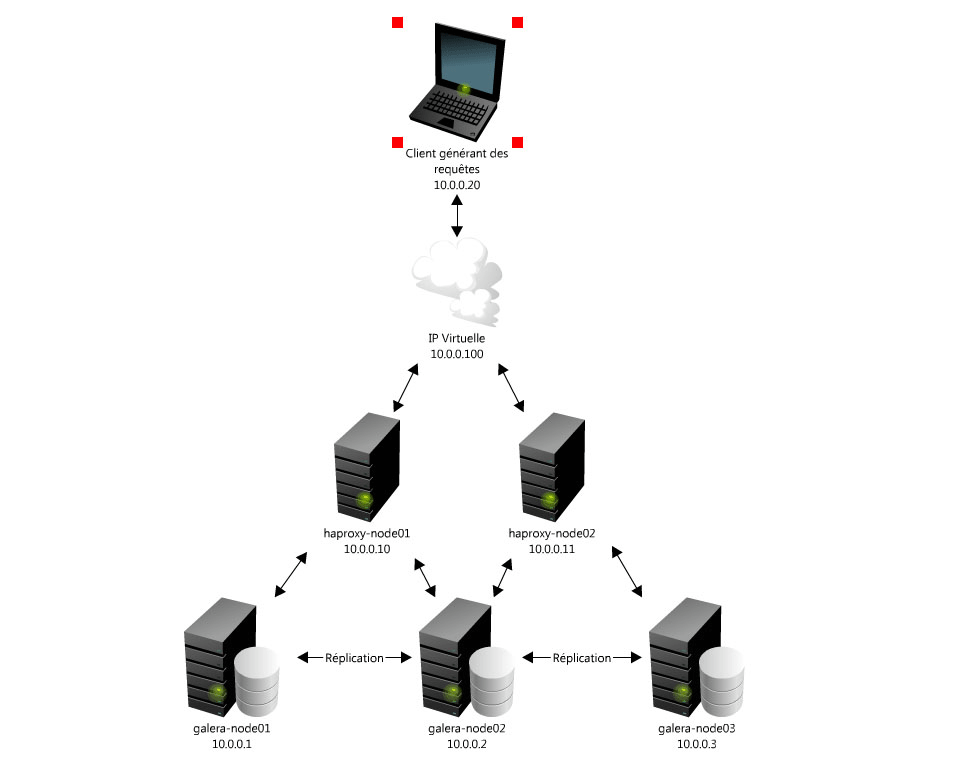
Here is the topology:
Pacemaker installation:
ubuntu@haproxy-node01:~$ sudo apt-get install pacemaker
We allow the start of corosync during the boot sequence and by the INIT script:
ubuntu@haproxy-node01:~$ sudo sed -i s/START=no/START=yes/ /etc/default/corosync
Same thing on the second node:
ubuntu@haproxy-node01:~$ ssh ubuntu@haproxy-node02 'sudo sed -i s/START=no/START=yes/ /etc/default/corosync'
Generate an authentication key for Corosync:
ubuntu@haproxy-node01:~$ sudo corosync-keygen
Corosync Cluster Engine Authentication key generator.
Gathering 1024 bits for key from /dev/random.
Press keys on your keyboard to generate entropy.
Press keys on your keyboard to generate entropy (bits = 64).
Press keys on your keyboard to generate entropy (bits = 128).
Press keys on your keyboard to generate entropy (bits = 192).
Press keys on your keyboard to generate entropy (bits = 256).
Press keys on your keyboard to generate entropy (bits = 320).
Press keys on your keyboard to generate entropy (bits = 384).
Press keys on your keyboard to generate entropy (bits = 448).
Press keys on your keyboard to generate entropy (bits = 512).
Press keys on your keyboard to generate entropy (bits = 576).
Press keys on your keyboard to generate entropy (bits = 648).
Press keys on your keyboard to generate entropy (bits = 712).
Press keys on your keyboard to generate entropy (bits = 784).
Press keys on your keyboard to generate entropy (bits = 848).
Press keys on your keyboard to generate entropy (bits = 920).
Press keys on your keyboard to generate entropy (bits = 984).
Writing corosync key to /etc/corosync/authkey.
It’s possible that you will have an issue using a SSH connection on a distant terminal. If it’s the case just generate random IO entropy with this line (run it on an another terminal):
$ while /bin/true; do dd if=/dev/urandom of=/tmp/100 bs=1024 count=100000; for i in {1..10}; do cp /tmp/100 /tmp/tmp_$i_$RANDOM; done; rm -f /tmp/tmp_* /tmp/100; done
We edit the corosync configuration file /etc/corosync/corosync.conf
interface {
# The following values need to be set based on your environment
ringnumber: 0
bindnetaddr: 10.0.0.0
mcastaddr: 226.94.1.1
mcastport: 5405
}
Be careful the bindnetaddr parameter is always a network or a sub-network.
We copy the key and the configuration on the other node:
ubuntu@haproxy-node01:~$ sudo scp /etc/corosync/authkey /etc/corosync/corosync.conf ubuntu@haproxy-node02:
ubuntu@haproxy-node02:~$ sudo chown root:root authkey corosync.conf
ubuntu@haproxy-node02:~$ sudo mv authkey corosync.conf /etc/corosync/
Check the key’s permissions:
ubuntu@haproxy-node01:~$ ls -al /etc/corosync/authkey
-r-------- 1 root root 128 2012-03-14 14:08 /etc/corosync/authkey
We run the corosync daemon on each node:
ubuntu@haproxy-node01:~$ sudo service corosync start
* Starting corosync daemon corosync
...done.
ubuntu@haproxy-node02:~$ sudo service corosync start
* Starting corosync daemon corosync
...done.
We test the connection between the nodes:
ubuntu@haproxy-node01:~$ sudo crm_mon -1
============
Last updated: Wed Mar 14 14:25:24 2012
Stack: openais
Current DC: haproxy-node01 - partition with quorum
Version: 1.1.5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
0 Resources configured.
============
Online: [ haproxy-node01 haproxy-node02 ]
Nodes are properly connected but not configured yet.
II.1. IP failover configuration
First of all, we have to setup the IP failover. Corosync will check every seconds if the other node is still alive. If the other node become unreachable, the current node will take the lead and the virtual IP address will target the new node.
ubuntu@haproxy-node01:~$ sudo crm
crm(live)# cib new conf-failover
INFO: conf-failover shadow CIB created
crm(conf-failover)# configure
crm(conf-failover)configure# primitive failover-ip ocf:heartbeat:IPaddr2 params ip=10.0.0.100 cidr_netmask=32 op monitor interval=1s
crm(conf-failover)configure# verify
crm_verify[3028]: 2012/03/14_15:38:26 ERROR: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
crm_verify[3028]: 2012/03/14_15:38:26 ERROR: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
crm_verify[3028]: 2012/03/14_15:38:26 ERROR: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid
crm(conf-failover)configure# property stonith-enabled=false
crm(conf-failover)configure# property no-quorum-policy="ignore"
crm(conf-failover)configure# verify
crm(conf-failover)configure# end
There are changes pending. Do you want to commit them? y
crm(conf-failover)# cib use live
crm(live)# cib commit conf-failover
INFO: commited 'conf-failover' shadow CIB to the cluster
crm(live)# quit
bye
Here is my configuration:
crm(conf-failover)configure# show
node haproxy-node01 \
attributes standby="off"
node haproxy-node02 \
attributes standby="off"
primitive failover-ip ocf:heartbeat:IPaddr2 \
params ip="10.0.0.100" cidr_netmask="32" \
op monitor interval="1s"
property $id="cib-bootstrap-options" \
dc-version="1.1.5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
rsc_defaults $id="rsc-options" \
resource-stickiness="100"
Here I simply created a primitive with the IPaddr2 agent, assigned a virtual IP address and set one second interval check. I also disable STONITH and the quorum policy.
Does it work?
ubuntu@haproxy-node01:~$ sudo crm_mon -1
============
Last updated: Wed Mar 14 17:55:18 2012
Stack: openais
Current DC: haproxy-node02 - partition with quorum
Version: 1.1.5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
1 Resources configured.
============
Online: [ haproxy-node01 haproxy-node02 ]
failover-ip (ocf::heartbeat:IPaddr2): Started haproxy-node01
II.2. HAProxy resource failover
Here we are managing the behavior of the HAProxy daemon. If a node is assigned as active the resource have to failover or failback. Since Pacemaker doesn’t provide a resource agent for HAProxy, we have to use a LSB agent using the INIT Script. Pacemaker will manage the start-stop-restart of HAProxy directly from the INIT script.
ubuntu@haproxy-node01:~$ sudo crm
crm(live)# cib new conf-haproxy
INFO: conf-haproxy shadow CIB created
crm(conf-haproxy)# configure
crm(conf-haproxy)configure# property stonith-enabled=false
crm(conf-haproxy)configure# property no-quorum-policy=ignore
crm(conf-haproxy)configure# primitive haproxy lsb:haproxy op monitor interval="1s"
crm(conf-haproxy)configure# colocation haproxy-with-failover-ip inf: haproxy failover-ip
crm(conf-haproxy)configure# order haproxy-after-failover-ip mandatory: failover-ip haproxy
crm(conf-haproxy)configure# verify
crm(conf-haproxy)configure# end
There are changes pending. Do you want to commit them? y
crm(conf-haproxy)# cib use live
crm(live)# cib commit conf-haproxy
INFO: commited 'conf-haproxy' shadow CIB to the cluster
crm(live)# quit
bye
Here is my configuration:
crm(conf-haproxy)configure# show
node haproxy-node01 \
attributes standby="off"
node haproxy-node02 \
attributes standby="off"
primitive failover-ip ocf:heartbeat:IPaddr2 \
params ip="10.0.0.100" cidr_netmask="32" \
op monitor interval="1s"
property $id="cib-bootstrap-options" \
dc-version="1.1.5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
You certainly already noticed that I disabled 2 pacemaker features and add the resource stickiness option:
STONITH: Shoot The Other Node In The Head, the goal of this functionnality is to avoid split-brain and isolate the corrupt node. This will completely physically shutdown the server (shutdown or restart) or shutdown the power. This is applicable for a 3 nodes configuration. If you want to know more about why you must use STONITH check this funny story and thoses explanations.Quorum policy: When you create a cluster, there is ideally 3 nodes for the high-availability purpose but it’s not mandatory. Three nodes are needed for a good communication between the nodes, for checking the healthstate of the others nodes and eventually taking the lead or managing the membership. Usually the quorum value is the name of the node, in our setup we only have 2 nodes, if one node goes down (the one the quorum policy/checksum), the whole cluster will fall. At the end, the quorum policy manages the node coordination, we need 3 nodes minimum.
Current DC: haproxy-node01 - partition with quorum
Resource stickiness: In order to prevent constent failover and failback, we often choose to disable the recovery and the failback of the resource. For instance, if the primary node goes down, the resource will be move on the secondary node. We went to prevent node from moving after recovery for this we gave it a major cost (weight). In fact moving a resource requires a little down time, this is why we will definitly use this option.
Does it work?
ubuntu@haproxy-node01:~$ sudo crm_mon -1
============
Last updated: Wed Mar 14 18:27:48 2012
Stack: openais
Current DC: haproxy-node02 - partition with quorum
Version: 1.1.5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
2 Resources configured.
============
Online: [ haproxy-node01 haproxy-node02 ]
failover-ip (ocf::heartbeat:IPaddr2): Started haproxy-node01
haproxy (lsb:haproxy): Started haproxy-node01
III. Stress!
In this section, I’m going to stress this architecture. I was needed to answer to a few questions like:
- How long does a failover take?
- Performance impact?
- How long does the recovery take?
Here some tests I runned:
- stop haproxy daemon
- stop corosync daemon
- resource migration
- stop a galera node
See the failover duration below:
$ for i in 1 2 3 ; do time mysql -uroot -proot -h10.0.0.100 -e "SHOW VARIABLES LIKE 'wsrep_node_name';" ; done
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node01 |
+-----------------+---------------+
real 0m0.008s
user 0m0.004s
sys 0m0.000s
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node02 |
+-----------------+---------------+
real 0m0.008s
user 0m0.004s
sys 0m0.000s
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node03 |
+-----------------+---------------+
real 0m0.007s
user 0m0.000s
sys 0m0.004s
III.1. Stopping HAProxy daemon
Here I suddenly stopped the HAProxy daemon, this one will be automatically restarted by corosync. I recorded the output in a text file called haproxy-stop-start.txt. At the beginning the raw output was:
real 0m0.015s
user 0m0.000s
sys 0m0.004s
ERROR 2003 (HY000): Can't connect to MySQL server on '10.0.0.100' (111)
I used this oneliner to custom the output:
$ cat haproxy-stop-start.txt | grep real | awk '{print $2}' | cut -f 2 -d 'm' | cut -f 1 -d 's' > secondes.txt
Latest output format:
0.003
Script duration calculator:
#!/bin/bash
total=0
for nbr in `cat secondes.txt`; do
total=`(echo $total + $nbr | bc -l)`
done
echo "Total = $total"
Script execution duration:
$ ./count
Total = 1.061
At the end, procedure took 1.061 seconds.
III.2. Stopping corosync daemon
Here it’s quite simple, I stopped corosync on the node 01, the resource should failover to the node 02. I used this command to trace:
$ while true ; do time mysql -uroot -proot -h10.0.0.100 -e "show variables like 'wsrep_node_name';" ; done
The output was:
real 0m0.008s
user 0m0.004s
sys 0m0.000s
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node03 |
+-----------------+---------------+
real 0m0.030s
user 0m0.004s
sys 0m0.000s
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0
real 0m0.019s
user 0m0.004s
sys 0m0.000s
ERROR 2003 (HY000): Can't connect to MySQL server on '10.0.0.100' (111)
real 0m0.005s
user 0m0.000s
sys 0m0.004s
ERROR 2003 (HY000): Can't connect to MySQL server on '10.0.0.100' (111)
real 0m0.004s
user 0m0.004s
sys 0m0.000s
ERROR 2003 (HY000): Can't connect to MySQL server on '10.0.0.100' (111)
real 0m0.005s
user 0m0.000s
sys 0m0.004s
ERROR 2003 (HY000): Can't connect to MySQL server on '10.0.0.100' (111)
real 0m0.005s
user 0m0.000s
sys 0m0.004s
ERROR 2003 (HY000): Can't connect to MySQL server on '10.0.0.100' (111)
real 0m0.003s
user 0m0.000s
sys 0m0.004s
ERROR 2003 (HY000): Can't connect to MySQL server on '10.0.0.100' (111)
real 0m0.004s
user 0m0.004s
sys 0m0.000s
ERROR 2003 (HY000): Can't connect to MySQL server on '10.0.0.100' (111)
real 0m0.004s
user 0m0.000s
sys 0m0.004s
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node01 |
+-----------------+---------------+
real 0m3.013s
user 0m0.000s
sys 0m0.008s
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node02 |
+-----------------+---------------+
It took 3 secondes to reconnect.
III.3. Resource migration
I just unexpectedly moved the resource to an other node. The resource was lead by the node 02.
ubuntu@haproxy-node01:~$ sudo crm_mon -1
============
Last updated: Wed Mar 14 22:09:54 2012
Stack: openais
Current DC: haproxy-node01 - partition with quorum
Version: 1.1.5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
2 Resources configured.
============
Online: [ haproxy-node01 haproxy-node02 ]
failover-ip (ocf::heartbeat:IPaddr2): Started haproxy-node02
haproxy (lsb:haproxy): Started haproxy-node02
How did I migrate the node?
ubuntu@haproxy-node01:~$ sudo crm
crm(live)# resource
crm(live)resource# migrate failover-ip haproxy-node01
crm(live)resource# quit
bye
I performed this check:
ubuntu@haproxy-node01:~$ sudo crm_mon -1
============
Last updated: Wed Mar 14 22:10:39 2012
Stack: openais
Current DC: haproxy-node01 - partition with quorum
Version: 1.1.5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
2 Resources configured.
============
Online: [ haproxy-node01 haproxy-node02 ]
failover-ip (ocf::heartbeat:IPaddr2): Started haproxy-node01
haproxy (lsb:haproxy): Started haproxy-node01
I re-used my duration calculator:
root@debian:~$ ./count
Total = .050
This time it only took 5 centisecondes to perform the hot migration.
III.4. Stopping a galera node
I just stopped the MySQL daemon on the node 02:
$ sudo for i in 1 2 3 ; do time mysql -uroot -proot -h10.0.0.100 -e "SHOW VARIABLES LIKE 'wsrep_node_name';" ; done
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node01 |
+-----------------+---------------+
real 0m0.007s
user 0m0.004s
sys 0m0.000s
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node03 |
+-----------------+---------------+
real 0m3.014s
user 0m0.004s
sys 0m0.000s
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node01 |
+-----------------+---------------+
real 0m0.008s
user 0m0.000s
sys 0m0.004s
I was a little bit worried about the duration, 3 seconds, especially for a virtual machine, it’s too long. Then I thought that was a HAProxy parameter. If you want to improve your failover duration you have to play with those parameters:
timeout connect 50
timeout client 3500
timeout server 3500
Quote from the HAProxy documentation:
If the server is located on the same LAN as haproxy, the connection should be immediate (less than a few milliseconds). Anyway, it is a good practice to cover one or several TCP packet losses by specifying timeouts that are slightly above multiples of 3 seconds (eg: 4 or 5 seconds). By default, the connect timeout also presets the queue timeout to the same value if this one has not been specified. Historically, the contimeout was also used to set the tarpit timeout in a listen section, which is not possible in a pure frontend.
I even tried to use lower parameters:
timeout connect 50
timeout client 1500
timeout server 1500
I got those times values:
$ sudo for i in 1 2 3 ; do time mysql -uroot -proot -h10.0.0.100 -e "SHOW VARIABLES LIKE 'wsrep_node_name';" ; done
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node03 |
+-----------------+---------------+
real 0m0.007s
user 0m0.004s
sys 0m0.000s
+-----------------+---------------+
| Variable_name | Value |
+-----------------+---------------+
| wsrep_node_name | galera-node01 |
+-----------------+---------------+
real 0m0.008s
user 0m0.004s
sys 0m0.000s
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0
real 0m1.507s
user 0m0.004s
sys 0m0.000s
That’s generated a MySQL issue, maybe due to a short timeout. Finally I was able to double speed the failover duration.
III.5. Still writing?
This is the most important question
“What will happen if a failover is operating during a commit in the database?”
The test:
$ mysql -uroot -proot -h10.0.0.100 -e "CREATE DATABASE stress ; USE stress ; CREATE TABLE teststress( id INT, name VARCHAR(255) )"
$ for ((i=0 ; 200 -$i ; i++)) ; do mysql -uroot -proot -h10.0.0.100 -e "USE stress; INSERT INTO teststress VALUES($i,'stress$i')" ; done
The only thing I was able to notice was:
“If the request is longer than the duration of the failover, data will continue to be commited, contrary if the request is shorter than the failover duration then the commit will stop during the failover.”
At the end, this failover cluster offers a great high-availability and keep the data consistency well. Next time I will use the same setup with a custom resource agent and I will also use Keepalived which is simplier to setup.