
The summit was exciting and full of good things and announcements. We had great Cinder sessions and an amazing Ceph/OpenStack integration session. I’ve led the Ceph/OpenStack integration session with Josh Durgin (Inktank). We had a good participation from the audience. I would like to specially thank Sage Weil, Haomai Wang, Edward Hope-Morley for their good inputs. The main purpose of this session was to gather ideas to improve the Ceph integration into Openstack. Eventually, we built a draft of the Icehouse’s roadmap. For those of you who were not attending the session and are curious to learn more about what’s going to happen in the next few months this article is for you!
Havana’s best additions
Let’s start with a picture of the current state of the integration:
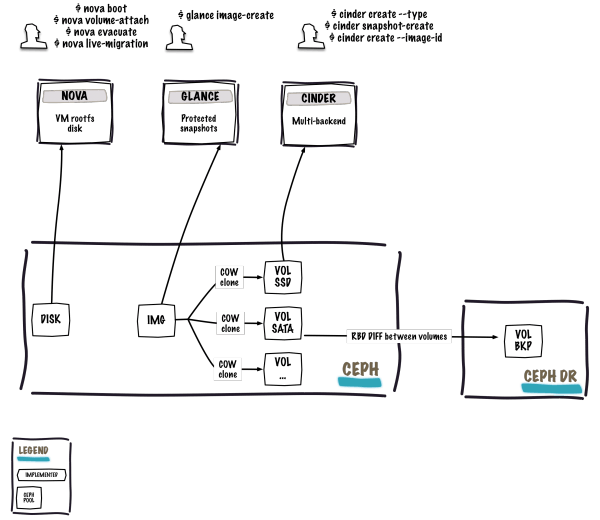
Before getting into the real stuff, I would like to highlight the current state of the integration by giving you a brief overview of the Havana’s best additions.
Complete refactor of the Cinder driver: we now use both librados and librbd. Previously the driver was ‘only’ made of shell commands called by the Python code. This wasn’t really elegant and didn’t give us a good error handling. This will make future development easier since we rely on the libraries.
Flatten volumes created from snapshots: immediately flatten volumes (clones) created from snapshots to remove any dependency between the clone and the snapshot. This is an operator decision. This is controlled by the
rbd_flatten_volume_from_snapshotflag. Just keep in mind that flattening clones increases the space used in your cluster.Clone depth: having to many chaining between snapshots, clones, parent and child images can cause some performance issues and could possibly break things at some point. A new Cinder option allows us to control the clone depth behavior. Then after a certain amount of clones (specified by the value in the
rbd_max_clone_depthflag, default is 5) the volume gets flattened.Cinder backup with a Ceph backend: prior to Havana, the cinder backup only had Swift as a backup backend. Havana brought the support of Ceph as a backend. Basically, the driver allows us to backup within the same Ceph pool (not recommended since it’s the same storage zone), backup between different Ceph pools (fine since this will be a different zone) or backup between different clusters (for disaster recovery purpose, backup from datacenter 1 to datacenter 2). The really good thing of this backend is that it brings a feature that was under discussion during the Cinder session: the support of an incremental backup API. Yes yes, if you perform a backup from a Ceph cluster to another, you get differential backups between the RBD images. This is really cost-effective. The backup driver also supports RBD stripes.
Nova
libvirt_image_type: by default, when you boot a virtual machine, its disk appears as a file on the filesystem of the hypervisor (usually under/var/lib/nova/instances/). Before Havana, thelibvirt_image_typeflag only had two backend: file and LVM. Now, it’s possible to specify RBD, this means that every new virtual machine that you boot will live inside Ceph. This is really cool because it allows us to easily perform maintenance operation with the live-migration process. On the other hand, if your hypervisor dies it’s also really convenient to triggernova evacuateand almost seamlessly run the virtual machine somewhere else.Cinder Volume QoS: this not directly related to Ceph, but since Ceph doesn’t currently support any form of QoS you can do it at the hypervisor level. Which is extremely good because you can allocate a certain amount of IOPS or bandwidth per client-basis (virtual machine). This is quite useful to restrict the usage of the whole platform while providing a good service level.
Icehouse’s roadmap
Ok now let’s get serious, we have a lot of things to implement and I truly hope that thanks to this article we will get some new contributors :-).
I will expose the roadmap component by component:
Bug fixing
Unfortunately, we started the Havana cycle with some bugs.
We’ve currently identified 4 bugs, which are already in the process of being fixed.
The most urgent one that needs to be addressed is the libvirt_image_type boot sequence.
The current workflow while booting a virtual machine with libvirt_image_type=rbd is the following:
- Glance streams the image from Ceph to the compute node
- Then the compute node imports the image into Ceph
- Eventually, the compute node boots the virtual machine
This is really inefficient and takes ages to boot the virtual machine. Since the backend for both Glance and Nova is Ceph, the solution is to create a copy-on-write clone of the image as soon as we boot the virtual machine. The action is directly performed at the Ceph level, it’s transparent and super fast to boot. We already do this with Cinder while creating a volume from an image. A fix is on the pipe.
For the remaining bugs and for those of you who are eager to use libvirt_image_type, Josh Durgin created a branch with all the fixes.
The last issue that we have is while creating a volume from an image, the source image doesn’t get converted into RAW format. In order to perform a boot from volume, the image format must be in a RAW format because QCOW is not supported. You can check the bug report to follow the progress.
Nova
Areas of work:
- Implement ‘bricks’ for RBD: brick is an initiative that aims to move every storage related pieces from all the OpenStack components to Cinder. Then Cinder hosts all the storage classes and all the OpenStack components can use them.
- Re-implement snapshotting function to use RBD snapshot: currently when you perform a snapshot, Nova uses QEMU snapshots, which means that you always get a full block based snapshot. With Ceph backing up all the instances disk, it is really inefficient since the backup file will go locally on the hypervisor and then will be streamed to Glance and finally uploaded into Ceph. From a performance perspective, it will be way easier to use Ceph RBD snapshot directly and much faster.
- RBD on Nova bare metal: since RBD offers a Kernel module for mapping virtual block device it could be really easy to implement such feature in nova bare metal. As a reminder, nova bare metal allows you to boot virtual machine that are actually physical bare metal host. Thanks to this, we can easily create a RBD image, enable the kernel module and map it to the host.
- Caching method while attaching a device: at some point and depending on your application using the block device, you would like to be able to either specify none, writethrough, writeback caching options. This is currently possible in OpenStack, however this will affect all the attached volumes, there is no way to specify the option for a specific volume. Eventually, the user will be able to decide which caching method is the most suitable for his device.
- Guest assisted snapshots: this provides filesystem-consistent snapshots while the volume is in-use. This could potentially be application-consistent if we use a customized QEMU guest agent. Many people are asking for consistent snapshots, this could be a first answer.
- Nova resize for instance booted into Ceph: while using
libvirt_image_typefor RBD we need to add the capability of resizing instance’s root disk when nova resize is called.
Cinder
Areas of work:
- Volume migration support: support the volume migration from one tenant to another and from one backend to another.
- RBD stripes support: support RBD stripes for cloud administrator and for cloud users. Basically, the Cloud operator can set a default value that could be overridden by a cloud user. For more information about RBD stripes please visit the Ceph documentation.
- iSCSI RBD for other hypervisor: since Emperor the iSCSI/tgt implementation has become more stable and all support is upstream. ceph.com provides the latest packages while Ubuntu 14.04 should get them sooner or later. Nothing is ready for Red Hat yet, however there are no limitations. Hypervisors such as VMware require iSCSI devices for their virtual machine disks. Thanks to this, we could easily boot virtual machine with VMware and even attach block devices.
- Incremental backups over other protocol: the current implementation uses the ceph-common package. The ‘rbd’ CLI is encapsulated into the Python code. Depending on the infrastructure, security policies might require more secure transactions. For instance, using SSH might be a good option.
Glance
Areas of work:
- Store snapshots and images to different locations: the main objective is to store images and snapshots into different pools since they don’t need the same availability level. While images are just flat OS (well this not entirely true since you can take a snapshot and then import it as an image), snapshots potentially host customers data. Some images like Windows RAW image can easily take 40GB, forcing a replica count of 3 for both images and snapshots is not really cost-effective. Typically as a cloud engineer, you would like to have a replica count of 2 for the images and a replica count of 3 for the snapshots.
Beyond, ‘J’ roadmap
New comers in OpenStack (projects).
- Manila support: Manila is a distributed filesystem as a service project. We can implement the CephFS support, I have already registered the blueprint on the launchpad.
- Swift multi-backend: Swift recently brought the support of several new object store backends (Kinetic) and new replication algorithms (ssync). Our goal here is to implement a RADOS driver that could be used by Swift. Ideally, we would like to have Swift talking to RADOS. Clients won’t be disturbed since the API won’t change and operators will be happy to have a unified storage platform. Thanks to this, the circle will be complete and Ceph will back every OpenStack components. Finally this is what the integration could look like tomorrow:
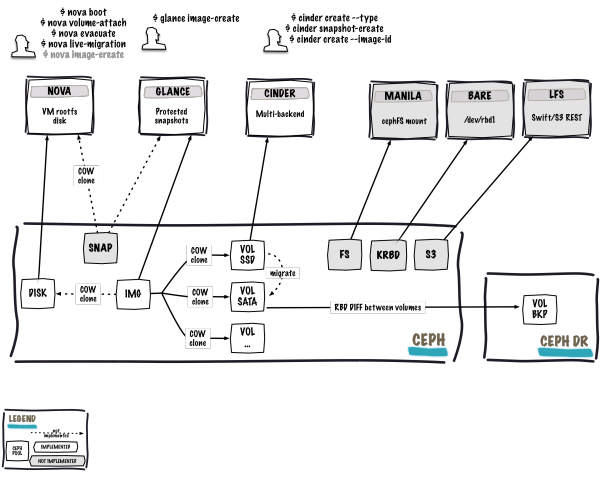
It’s pretty obvious that we have plenty of work to do for Icehouse. Once again, contributors are more than welcome. So if you want to integrate the future of storage into OpenStack, don’t hesitate and to drop me a line so we can discuss and coordinate our efforts. At eNovance, we already started to work on the Swift multi-backend driver for RADOS, because we believe that this is a huge step forward to Ceph’s integration into OpenStack. Also please don’t forget that the Ceph Developer Summit is just around the corner, I will be more than happy to have folks discussing this subject. This will be an online event on IRC and Google hangouts. You can always check the official announcement and don’t forget to register blueprints as well. I look forward chatting with you guys!