
Ceph IO patterns analysis final part: The Ugly.
Before starting, I would like to step back a little bit. What I’m going to expose is not only Ceph related but more general to distributed storage system. So yes, this is ugly but it is not only for Ceph, so please keep this in mind.
The ugly
I.1. IO patterns on RBD
One IO into Ceph leads to 2 writes, well… the second write is the worst!
Principle:
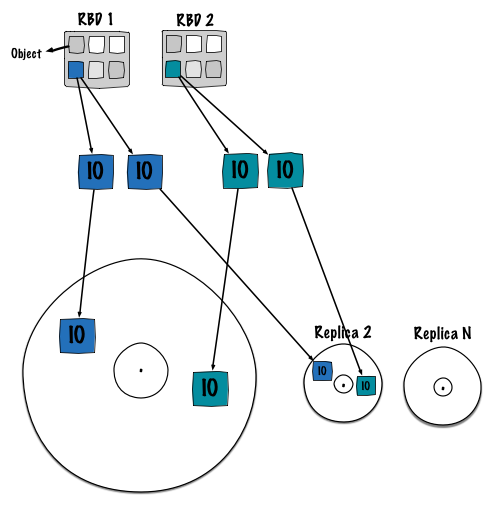
During my last benchmarking session we had a similar assumption, however we didn’t get the chance to bring to light this fact. Fortunately people from Intel transformed this assumption into a reality. The phenomena is pretty easy to understand. Basically and due to its distributed nature Ceph deterministically stores objects. Thus, objects (from diverse clients) will map to the same OSD disk. Eventually sequential streams get mixed all together. Ceph queues IO operation, for instance you could get the following one:
- object1 points to pg1.1
- object2 points to pg1.2
- object3 points to pg1.3
- object4 points to pg1.4
- object5 points to pg1.5
And OSD 1 is responsible for these 5 PGs.
However no one knows how and where these 5 directories on the filesystem (/var/lib/ceph/osd/osd.1/current/pg1.{1,2,3,4,5}) appear to be on the block device.
As shown on the picture, PGs have a determined (by the filesystem) position on the block device.
To conclude, the disk spends most of its time jumping from one track to another, decreasing overall performance.
Since I hate paraphrasing, I’m gonna guide you to the excellent blog post from Intel guys here that explains the behavior in more details.
I.2. It might be even worse with erasure coding
Reusing Loic Dachary’s picture.
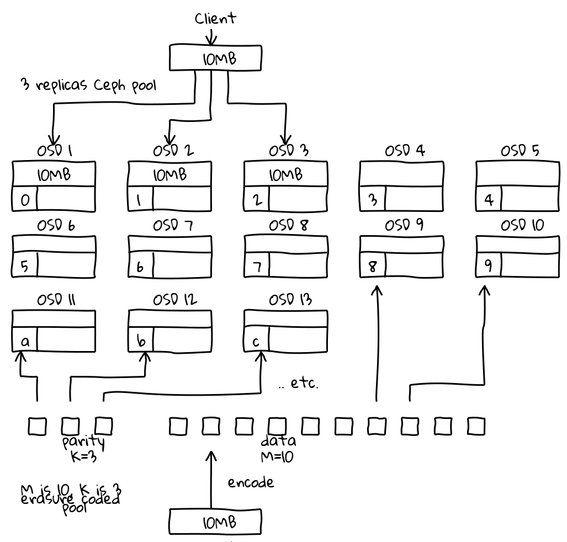
This is just an assumption. The previous phenomena could potentially get amplified, since erasure code doesn chunks of chunks. As shown on the picture, instead of writing 3 objects we write 13 objects: 10 x 1M (cut) + 3 (parity). I believe erasure code will save you space but it will also bring down your performance.
You must verify this.
The last two sections are a bit moving from the IO pattern theme but I believe they are important to take into consideration.
II. Memory bit corruption
Memory bit corruption is when you have a bit shifting from a position. On a distributed replicated enviromment like Ceph, this could potentially lead to large data corruption since the corruption will be simply spead accross the entire cluster. Having a bit shift, can be tricky to notice because the client writes a file and then the file gets directly corrupted as soon as it enters the Ceph cluster. It is a general good practice to use ECC memory to prevent this kind of incidents.
For more details, read the Wikipedia page.
III. Software Defined Storage
Ceph is storage defined storage, which means that all your IOs are computed, stored and balanced with the help of a software entity programmed by humans. Thus a software failure for whatever reason could destroy all of your data. We have seen in the past features or flags in Ceph that led to data corruption, unfortunately as soon as you discover that it is already too late. I understand that this is the worst scenario ever but the probability is here.
This article marks the end of my IO pattern analysis, I truly hope that these articles helped you to get a better understand of the Ceph internals.