
A new way to efficiently store objects using BlueStore.
As mentioned in an old article, thing are moving fast with Ceph and especially around store optimisations. A new initiative was launched earlier this year, code name: NewStore. But is it about?
The NewStore is an implementation where the Ceph journal is stored on RocksDB but actual objects remain stored on a filesystem. With the help of BlueStore, objects are now stored directly on the block device, without any filesystem interface.
I. Rationale
What was wrong with FileStore? As you may Ceph stores objects as files on a filesystem, this is basically what we call FileStore. If you want to learn more, please refer to a previous article where I explained Ceph under the hood. So now, let’s explore why the need of BlueStore emerged.
I.1. Safe transactions
Ceph is software defined storage solution, so its main purpose is to have your data stored safely and for this we need atomicity.
Unfortunately there is no filesystems that provide atomic writes/updates and given that O_ATOMIC never made it into the Kernel.
An attempt to fix this using Btrfs (since it provides atomic transactions) was made but did not really succeed.
Ceph developers had to find an alternative. This alternative you know it pretty well and it is the Ceph journal. However doing write-ahead journaling has a major performance cost since it basically splits performance of your disk into two (when journal and osd data share the same disk).
I.2. Objects enumeration
In the context of Ceph, storing objects as files on a POSIX filesystem is not ideal too.
Ceph stores object using a hash mechanism, so object names will appear in a funky way such as: rbdudata.371e5017a72.0000000000000000__head_58D36A14__2.
For various operations such as scrubbing, backfill and recovery, Ceph needs to retrieve objects and enumerate them.
However, POSIX does not offer any good way to read the content of a directory in an ordered fashion.
For this, Ceph developers ended up using a couple of ‘hacks’ such as sharding object directories in tiny sub directories so they could list the content, sort it and then use it.
But one again in the end, it is another overhead that is being introduced.
II. Anatomy
This is an overview of the new architecture with BlueStore:

In terms of layer of abstractions, the setup and his overhead are quite minimal. This is a deep dive into BlueStore:

As we can see, BlueStore has several internal components but from a general view Ceph object (actual ‘data’ on the picture) will be written directly on the block device. As a consequence we will not need any filesystem anymore, BlueStore consumes a raw partition directly. For metadata that come with an OSD, those will be store on a RocksDB key/value database. Let’s decrypt the layers:
- RocksDB, as mentioned is the global entity that contains the WAL journal and metadata (omap)
- BlueRocksEnv is the interface to interact with RocksDB
- BlueFS is a minimal C++ filesystem-like, that implements the rocksdb::Env interface (stores RocksDB log and sst files) Because rocksdb normally runs on top of a file system, BlueFS was created. It is a backend layer, RocksDB data are stored on the same block device that BlueStore is using to store its data.
So what do we store in RocksDB?
- Objects metadata
- Write-ahead log
- Ceph omap data
- Allocator metadata, the allocator is responsible for determining where the data should be stored. Note that this one is also pluggable.
Now, default’s BlueStore model on your disk:
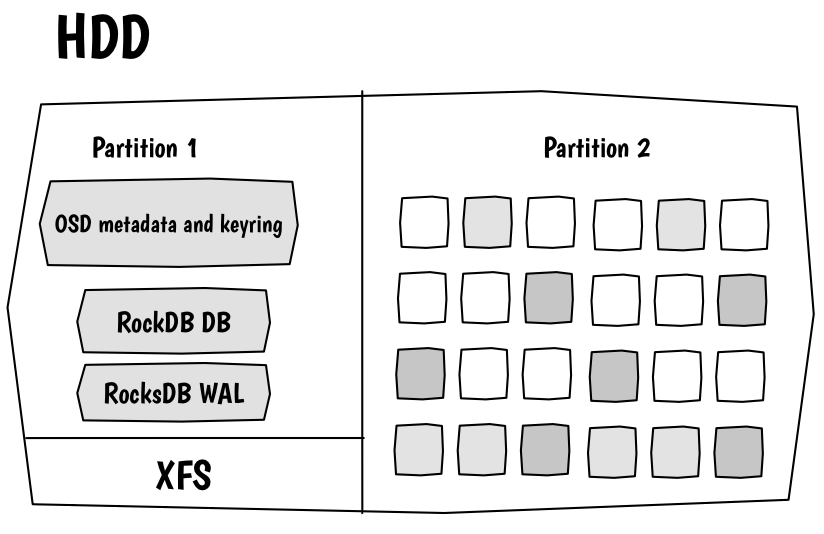
Basically, we will take a disk and partition it in two:
- the first tiny partition will be partitioned using either XFS or ext4. It contains Ceph files (like init system descriptor, status, id, fsid, keyring etc)
- the second is a raw partition without filesystem
And then an advanced BlueStore model:

What’s fascinating about BlueStore is to see how flexible it is.
Every component can be stored on a different device.
In this picture, RocksDB WAL and DB can be either stored on different devices or on tiny partitions too.
Those files don’t exist by default since RocksDB WAL and DB are stored on the RAW block device.
Optionally, a symlink can be used to point those to other block devices.
They will respectively be named: block.wal and block.db.
III. Key features
In order to summarize, let me highlight some of the best features from BlueStore:
- No more double writes penalty, as it writes directly on the block device first and then updates object metadata on RocksDB that specifies its location on the drive.
- Setup flexibility: as mention in the last section BlueStore can use up to 3 drives, one for data, one for RocksDB metadata and one for RocksDB WAL. So you can imagine HDD as a data drive, SSD for the RocksDB metadata and one NVRAM for RocksDB WAL.
- Raw block device usage: as we write directly to a block device we do not suffer the penalty and the overhead of a traditional filesystem. Plus we avoid the redundancy of journaling metadata where filesystems already do their own internal journaling and metadata management.
As soon as Jewel is released, BlueStore will be available. If I’m not mistaken it will be available but let’s consider it as a tech preview, I’m not sure yet if we should put it in production. To be sure carefully read the release changelog as soon as it is available. As we can see, Ceph is putting more and more intelligence into the drive. BlueStore is eliminating the need of the WAL journal dedicated journal with the help of RocksDB. I haven’t run any benchmarks on BlueStore yet but it is possible that we will not any dedicated device for journaling anymore. Which brings awesome perspectives in terms of datacenter management. Each OSD is independent, so it can be easily plugged out a server into another and it will just run. This capability is not new and if I remember correctly this was introduced during Firefly cycle thanks to the udev rules on the system. Basically when you hotplug a new disk containing an OSD on a system, this will trigger a udev event which will activate the OSD on the system. BlueStore simply strengthens this mechanism given that it removes the need of a dedicated device for the Ceph journal depending on what you want to achieve with your cluster. Performance running everything on the same drive should be decent enough for at least Cost/capacity optimized scenarios and potentially throughput optimized.