
For those of you who are not familiar with the concept yet, I’m going to give a quick introduction on Hyperconverged infrastructure.
Hypercon… What?
The way I like to put it is rather simple. Do not think too much, the word hyperconvergence or hyperconverged infrastructure is yet one of those buzz words. However the concept behind this is quite simple. An hyperconverged node is a server where compute and storage services are collocated. The world of Software Defined Network/Storage allows us to build such architectures. In the rest of the article, I will refer Hyperconverged Infrastructure as HCI.
These kind of design have numerous advantages:
- reduce hardware footprint by increasing its utilisation, we put more processes on one machine
- Guest can potentially benefit from a local hit when performing IOs
Containers to the rescue!
Note that usually HCI should be achieved with the help of containers. It is obviously possible to do it without containers but this rises a couple of challenges when it comes to resources control. If you don’t do this kind of control, we could end up into really bad scenarios like CPU and/or memory starvation, processes utilizing all the resources of the machine and stepping on each other. Usually this usage control is being done by the Kernel control groups, known as cgroups. cgroups are normally used for (source Wikipedia: cgroups):
- Resource limiting – groups can be set to not exceed a configured memory limit, which also includes the file system cache
- Prioritization – some groups may get a larger share of CPU utilization or disk I/O throughput
- Accounting – measures a group’s resource usage, which may be used, for example, for billing purposes
- Control – freezing groups of processes, their checkpointing and restarting
So for each process running on a machine, a special cgroup profile is being created. On this profile, we apply several set of parameters that will restrain processes behaviour. So from an operational perspective, the operator will have to manually setup these profiles for each processes. Note that on a compute node, we are up to 4 processes for OpenStack and N processes for each Ceph OSD.
With the use of containers, these challenges fade away, since everything is built-in and provided by the container engine out of box. So while running a new container, it will automatically (based on how the container engine is configured) a cgroups profile, nothing to configure.
Fine control of resources
We just saw that containers with the help of cgroups (under the hood) can help us restraining processes consumption.
However there is more to that, we haven’t touched things like NUMA and CPU pinning yet.
When it comes to the KVM hypervisor, there is an option in Nova that can be used to limit memory usage of the hypervisor itself: reserved_host_memory_mb.
This option must be used and set to your convenience (depending on your hypervisor).
NUMA awareness is also crucial to your HCI setup, ideally if you two sockets on your machine, each will get its own NUMA zone.
CPU pining, is something that has to be configured as part of Nova and instances flavors, so we will leave one sockets for the OpenStack instances and 1 socket for the Ceph storage daemons.
This won’t prevent you to set a specific cpu_allocation_ratio to that socket.
In our HCI Compute and Ceph we want to isolate virtual machine resources from Ceph storage daemons.
Because a picture speaks better than a thousand words:
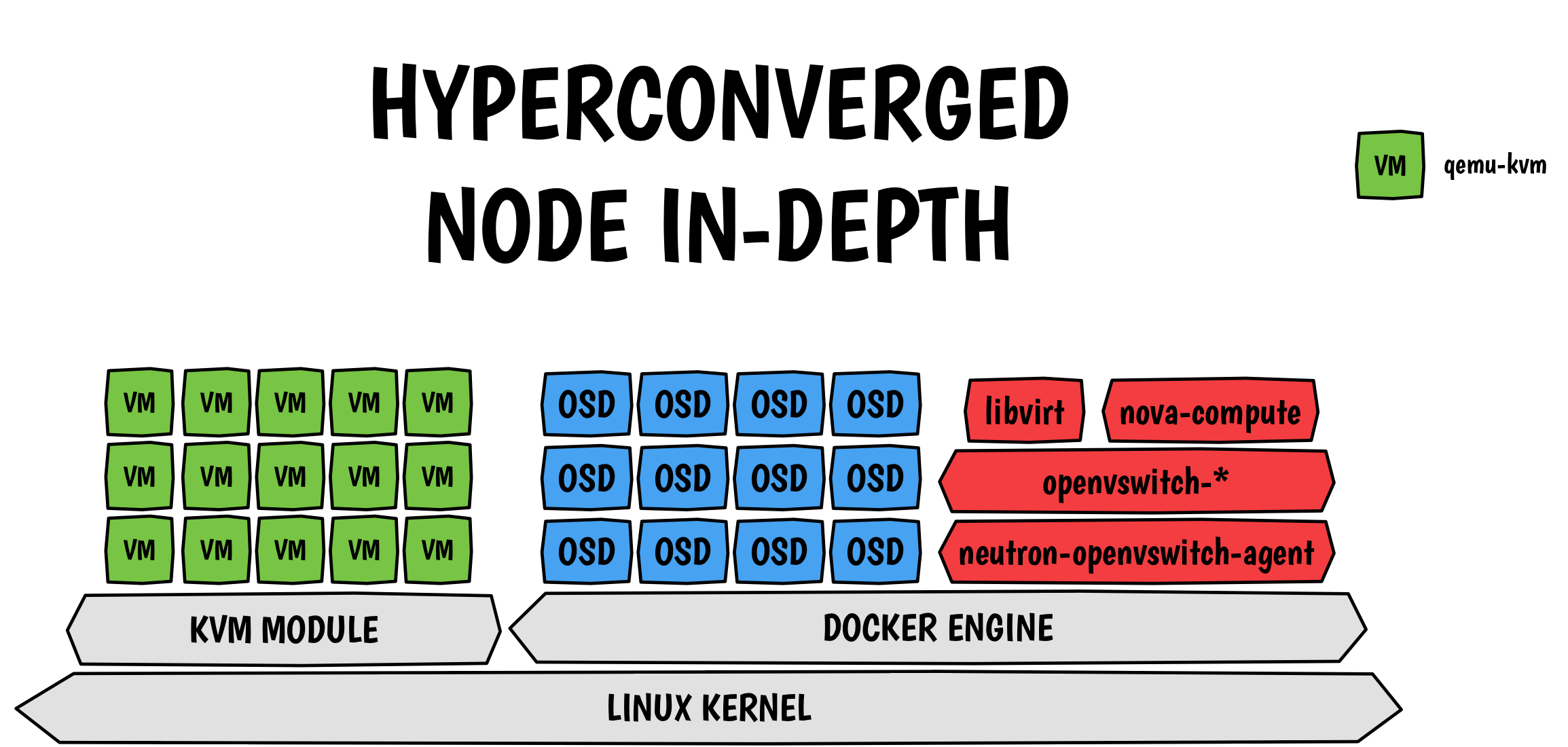
Every boxes in the picture above is a container, even the virtual machines.
I already talked about HCI in some of my presentations at the Red Hat summit, so don’t hesitate to have a look!