Respawn a pacemaker cluster
Issue type: pacemaker nfs/drbd cluster
- 6 posts all around the web
- 2 deviant from my configuration
- the rest.. no answer.
Seems legit.
Issue type: pacemaker nfs/drbd cluster
Seems legit.
Working with DRBD it’s not always easy, espacially when you add extra layer like pacemaker to bring high-availability to your platform. I’ve recently been through a weird issue with my high fault tolerance pacemaker cluster which is composed of 3 resources:

Some useful tips and tricks for managing your pacemaker cluster.
Sometimes you want to provide high availability on a service. Unfortunately there is no resource agent available by the provider. Thus you have to use the LSB script, which is also fine. Before that you just have to be sure that your LSB script is compatible. I wrote a simple bash script to figure this out :).
As promised, I will use a custom ocf agent for managing my HAProxy cluster

Here I’m going to setup high-availability features in our current infrastructure. I will add a new HAProxy node and will use pacemaker.
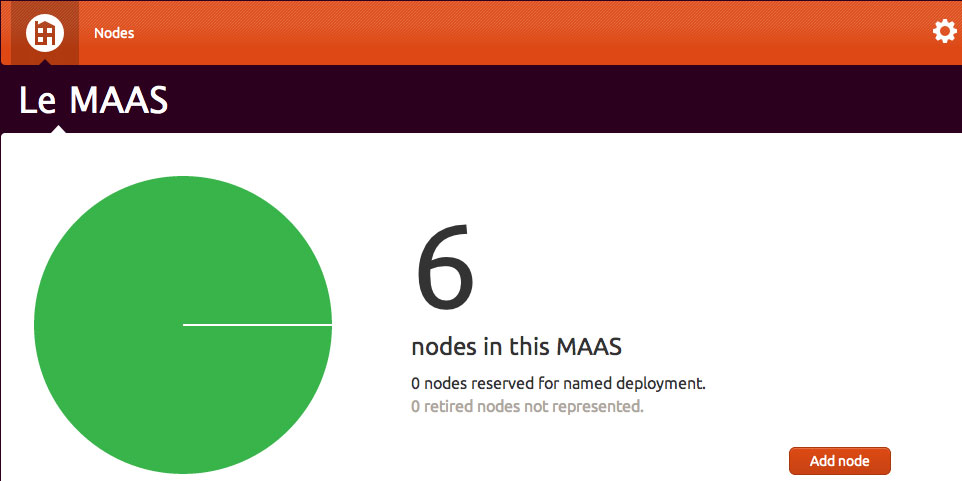
Couple of days ago Canonical annonced his new tool called MAAS, Metal as a Service. It makes it easy to set up the hardware on which to deploy any service that needs to scale up and down dynamically. With a simple web interface, you can add, commission, update and recycle your servers at will. As your needs change, you can respond rapidly, by adding new nodes and dynamically re-deploying them between services. When the time comes, nodes can be retired for use outside the MAAS. First test, impressions and some feedback.
![]()
When I started working on Open Stack, I had to investigate about the HA of the nova component. Unfortunatly the nova configuration needed a single entry point to connect to the MySQL database. The solution that came to me was to use HAProxy on top of my existing Galera cluster.

Setup MySQL master-master replication with Galera
SImple SSH whitelist